AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
こんにちは!RCOのエンジニアのような、そうでないような、量子重なり状態的な本橋です。今回のテックブログでは、決定木モデルの改良を目的にした、将来の量子アニーラーの活用を見据えたQUBOによる交互作用を考慮した2分類問題の決定木モデルの学習アルゴリズムの研究を紹介します。
なぜ決定木モデルを改良しようとしているのか?
決定木モデルは、古くからある有用な機械学習モデルの1つです。特に近年、XGBoostというライブラリの出現によって、勾配ブースティング木といった決定木モデルをベースにしたアンサンブル学習が有用であると認知され、広く利用されています。また、勾配ブースティング木以外にもランダムフォレストといった別の決定木モデルをベースにしたアンサンブル学習も人気であり、広く利用されています。
しかし、アンサンブル学習モデルのベースになっている決定木モデルには弱点があります。それは、単体では有効な特徴量ではないが、特徴量を組み合わせることによって有効になる特徴量を選択しづらいという弱点です。通常の決定木モデルの学習アルゴリズムでは、常に指標の値が最も良い特徴量とその閾値を1つずつ採択するため、単体で説明力のある特徴量の方が採択されます。そのため、このような弱点があります。
恣意的なサンプルデータを用いて具体的に決定木の弱点を解説します。例えば、下記のようなデータセットを用いた、深さ2の決定木モデルの学習について、考えてみましょう。
| No | 予測変数 | 特徴量A | 特徴量B | 特徴量C | 特徴量D |
|---|---|---|---|---|---|
| 1 | True | 5 | a | 2 | 2 |
| 2 | True | 5 | a | 6 | 5 |
| 3 | True | 10 | b | 4 | 5 |
| 4 | True | 10 | b | 5 | 3 |
| 5 | False | 10 | a | 2 | 4 |
| 6 | False | 10 | a | 6 | 2 |
| 7 | False | 5 | b | 2 | 5 |
| 8 | False | 5 | b | 6 | 4 |
ジニ不純度を指標として、決定木(CART)を利用して学習した場合、決定木モデルは下記のようになります。
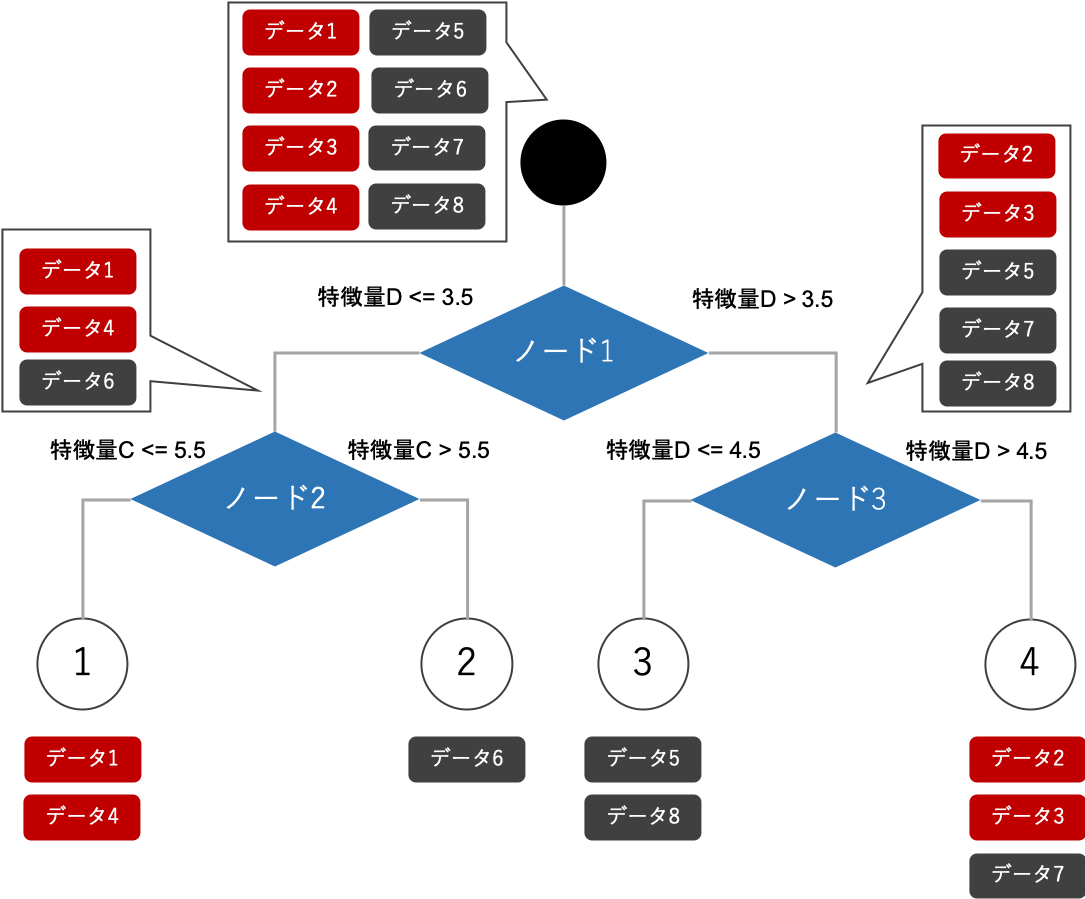
作成されたモデルの図のように、単体で有効な特徴量Dが最初のノードに採択され、さらに下のノードでも単体で有効な特徴量Cが採択されています。しかし、実は特徴量AとBを採択した下記のような決定木モデルを構築すると、全てのデータを正確に分類することができます。
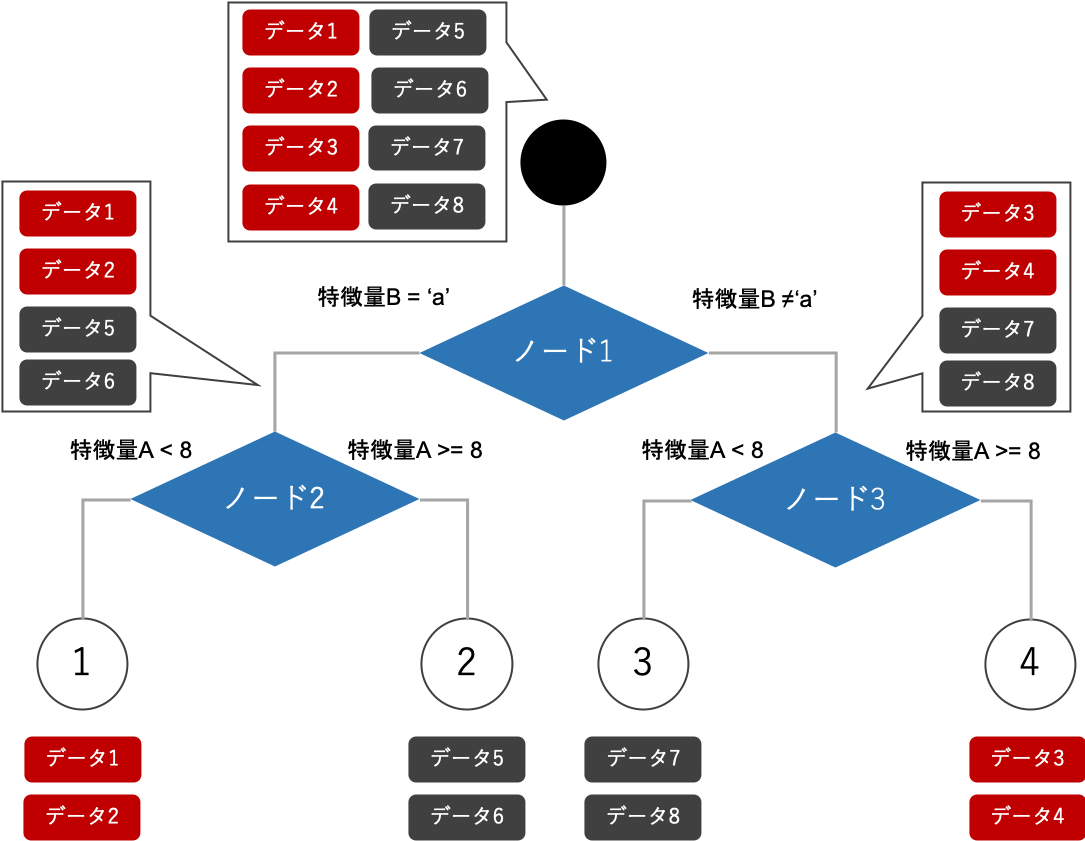
このように、通常の決定木モデルでは、特徴量を組み合わせることによって有効になる特徴量を発見することができません。本研究では、この問題の解決を目指しています。
2階層同時に学習する決定木モデルは有効なのか?
先ほどは、決定木モデルの弱点を例示しましたが、この問題は恣意的なデータセットであり、現実のデータセットにも当てはまるのかはまだ分かりません。そこで、この項では現実のデータセットを用いて、この問題点を解決することが精度向上につながるのかを確認します。
特徴量の組み合わせを考慮した決定木モデルは、実は簡単に作ることができます。それは、複数の階層に対する特徴量と閾値の組み合わせを同時に探索し、最も良い指標となる組み合わせを採択するアルゴリズムを採用することです。このアルゴリズムが検討する特徴量と閾値の組み合わせパターンは、通常の決定木アルゴリズムが検証する特徴量と閾値の組み合わせパターンを包含しています。そのため、このアルゴリズムの学習データ対する採用指標の値は、必ず通常の決定木アルゴリズムと同等かそれ以上に優れています。
ただし、複数の階層を同時に学習する決定木モデルには大きな問題点があります。それは、学習時間が長くなってしまうという問題点です。例えば、特徴量が10種類あり、各特徴量の閾値の候補が100種類あった場合、深さ2の決定木モデルが探索するパターン数は、下記のようになります。
- 通常の決定木モデル: (100 * 10) * 3 = 3,000 パターン
- 2階層を同時に学習する決定木モデル: (100 * 10) ^ 3 = 1,000,000,000 パターン
このように2階層を同時に学習するだけで、3千パターンから10億パターンまで跳ね上がるため、モデルの学習時間が跳ね上がってしまいます。この差は、特徴量や閾値の種類数が増えるほど大きくなります。ただし、一定の問題規模においては、検証するパターンを間引けば、許容できる計算時間内で解くことはできます。そこで本検証では、簡易的な2階層を同時に学習する決定木アルゴリズムと通常の決定木アルゴリズムを実装し、公開されている分類問題において精度が改善されることがあるか検証を行いました。
簡易的な2階層を同時に学習する決定木アルゴリズムでは、各特徴量の閾値候補を全パターンにせずに、間引いた少数のパターンを採用しました。特徴量が数値の場合の閾値候補は、データ数基準に10等分できる9種類の閾値を候補として採用しています。特徴量が論理値/カテゴリ値の場合の閾値候補は、論理値/各カテゴリをダミー化した値のTrue/Falseの2種類の閾値を候補として採用します。
簡易的な2階層を同時に学習する決定木アルゴリズムにおいて、深さ3以上の決定木を検討する際には、学習した木の最下層の各ノードにおいて簡易的な2階層を同時に学習するアルゴリズムを繰り返すことで実現しています。
検証結果は、下記の表に示しています。検証には、分類問題のオープンデータを利用し、交差数4の交差検証を用いました。パラメータは、下記のパラメータ探索範囲から、各手法において学習データ上で最も精度が良かったものを選択しました。モデル精度の比較は、検証データの精度を利用しています。下記の検証結果の表には、学習データにおいて最も精度が良かったパラメータにおける検証データの精度を記載しています。
パラメータ探索範囲 - 分岐するために最低限必要なデータ数:50, 100, 200 - 決定木の最大深さ:2, 4, 6 - 分類基準の指標:ジニ不純度
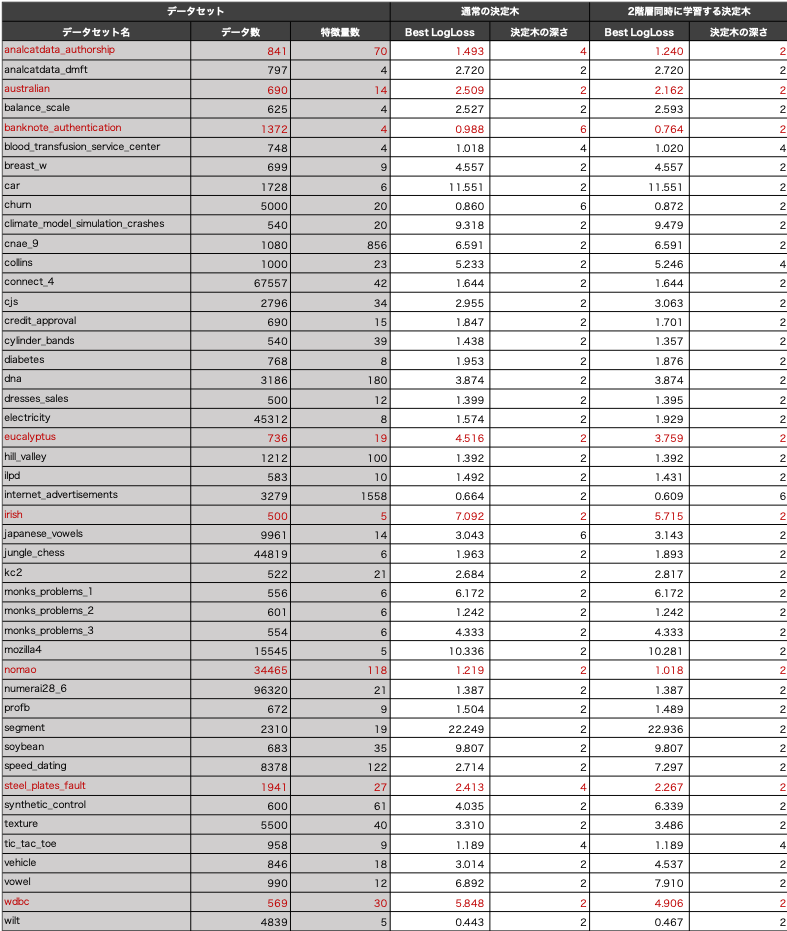
この検証によって、特徴量の組み合わせを考慮することによって精度が上がるようなケースが実際の問題にも存在するのかを確認しました。上記の検証結果から、一部の問題において特徴量の組み合わせが精度の向上に繋がっていることが読み取れます。特に、analcatdata_authorshipやbanknote_authenticationにおいては、従来の決定木モデルよりも深さが浅い上にモデル精度も高くなっています。これは、2階層を同時に学習することでデータによりフィッティングしやすくなるため、過学習が進みやすいということがある一方、逆に小さな自由度のモデルで十分な分類性能を表現でき汎化性能が向上できるケースも見られることを示しています。
以上のように、2階層を同時に学習する決定木モデルは、現実の問題でも有効なケースがあることが示されました。しかし、閾値の候補数や特徴量数が増えると計算時間が膨大になる問題点は解決していません。そこで、学習の高速化の実現するために、QUBOによって2階層同時に学習する決定木モデルを実現することで、イジングマシンや量子アニーラー活用できるようにすることを目指します。
QUBO形式の定式化を考える。
イジングマシンや量子アニーラーの詳しい説明は、本記事では省略しますが、QUBO形式で定式化することができれば、イジングマシンや量子アニーラーを活用することができます。本項では、2階層を同時に学習する決定木モデルのQUBO形式での定式化について説明します。(QUBOの詳しい説明は、こちらをご覧ください。)
問題の定式化には、様々な表現方法がありますが、本記事では、多数の定式化表現方法を比較し見つかった最も実用性が高そうな定式化の表現を紹介します。
定式化の説明は、下記の4つのパートに分けて説明します。 - 定式化の決定変数 - 特徴量の選択の制約式 - データ分割に関する式 - モデルの分類精度に関する式
定式化の決定変数
本研究の定式化は、$x _{na}$と$y _{nb}$の2種類のバイナリ決定変数(最適化問題で決定する0または1をとる変数)を利用しています。決定変数$x _{na}$は、決定木モデルのノードおよび学習データ毎に存在します。決定変数$x _{na}$は、「ノード$n$」における「データ$a$」の分岐方向を表します。決定変数$y _{nb}$は、決定木モデルのノード毎および特徴量の種類毎に存在します。決定変数$y _{nb}$は、「特徴量$b$」を「ノード$n$」における分岐基準への採用有無を表しています。
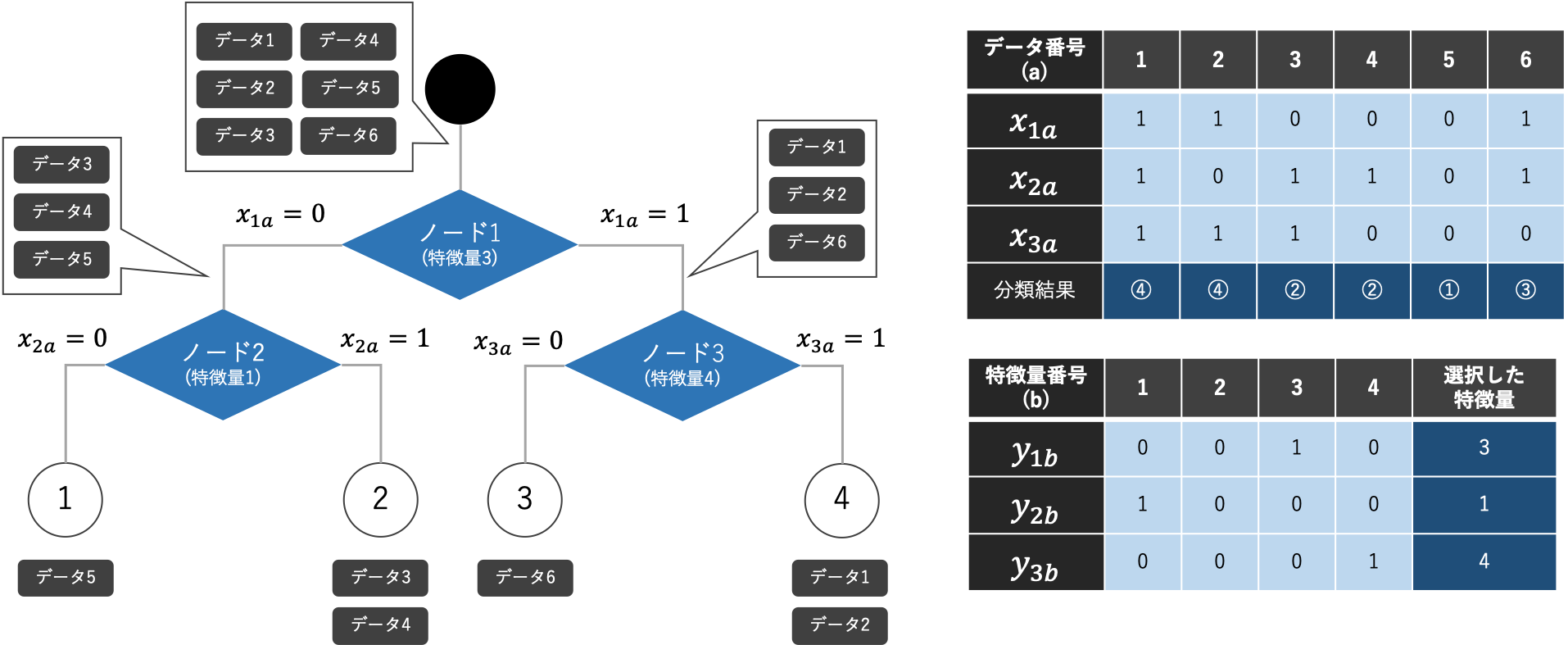
決定変数$x _{na}$と$y _{nb}$を決定することによって、決定木モデルを学習することができます。一部の方は、ノードの閾値を直接表現した決定変数がなく、定式化の表現方法に疑問を持つかもしれません。しかし、決定変数$x _{na}$と$y _{nb}$が決定すれば閾値を計算することができるのです。
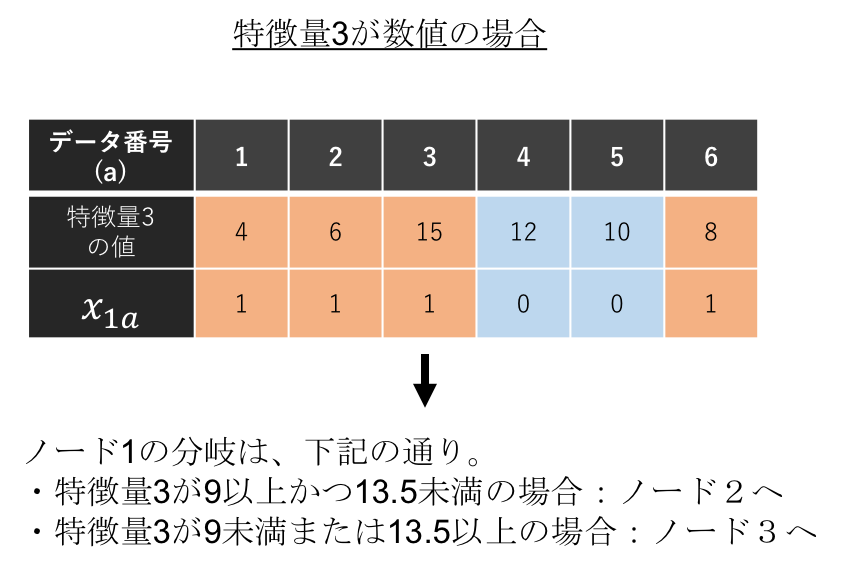
下の図はその例です。ノード1で特徴量3が選択されているとします。左の図は特徴量3が数値の場合ですが、特徴量の値でデータを並び替え、データ分岐している箇所の間の値を閾値に採用することができます。右の図は特徴量3がカテゴリ値の場合ですが、特徴量の値ごとに分岐先を把握することができます。

さらにこの定式化の方法の場合、下の図のように、分岐基準の特徴量が数値の場合において複数の閾値を用いた分岐も表現することができます。
特徴量の選択の制約式
各ノードで分岐基準に選択される特徴量は、必ず1つである必要があります。よって、あるノード$n$を対象とした決定変数$y _{nb}$は、いずれか1つが1となり、それ以外が0になる必要があります。つまり、ノード毎の$y _{nb}$の合計値が1になる必要があります。QUBOにおいては、合計値が1とならない場合ペナルティがかかる式を下図のような式で表現します。この制約はどんな場合も必ず満たさないといけない制約式であるため、制約式で出てくるペナルティ係数は十分に大きな値を設定する必要があります。

データ分割に関する制約式
各ノードは、分岐基準にした特徴量の値に基づき分岐する必要があります。これらの分岐基準は、特徴量の値の種類によって異なります。
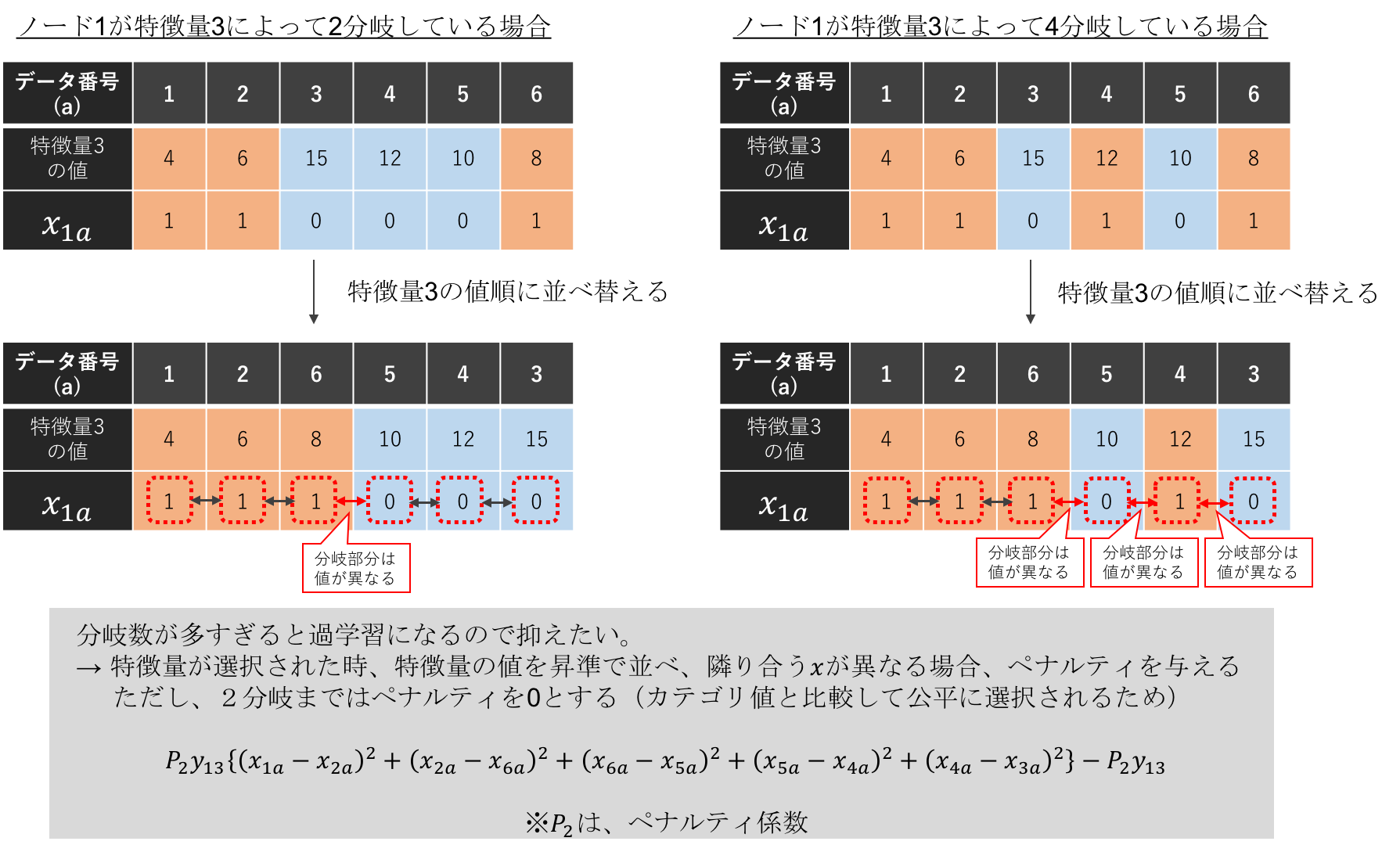
最初に、最上部のノードの分岐基準の特徴量が数値型の場合に関して説明します。一般的な決定木モデルでは、分岐基準の特徴量の値と閾値の大小関係を比較した結果に応じて2分岐させます。下図の左側の例に該当します。一方、右側の例は、特徴量3の値が、「9未満」または「11以上14未満」の場合:1、「9以上11未満」または「14以上」の場合:0といった閾値が9,11,14の3つもあるような分岐になっています。必ずしも閾値が1つである必要はありませんが、閾値の数が多くなるほどモデルの自由度が上がり、過学習を引き起こしやすくなってしまいます。そのため、閾値の数を抑制する必要があります。
下図をみてわかるように、「分岐基準の特徴量を数値順に並べた時に隣り合う決定変数$x _{na}$の値が異なる数」と「閾値の数」は同数であることが分かると思います。つまり、分岐基準にした特徴量を数値順に並べた時に隣り合う決定変数$x _{na}$の値が異なる数が多いほどペナルティを与える式をQUBOに加えることによって、分類精度の向上度合いと閾値の数のトレードオフを考慮しながら閾値を探索できます。そこでQUBOにおいては、下図の下部のような、「ある特徴量の値で並び替えた場合の隣あう決定変数$x _{na}$が異なり、さらにある特徴量が選択された場合」にペナルティがかかる式で表現します。さらに、「ある特徴量が選択された時には、閾値1つの場合はペナルティがかからないようにペナルティ係数と決定変数$y _{nb}$の積を引いています。これは、カテゴリ値におけるデータ分割の制約式と公平な条件にするためです。
この制約式は、ペナルティ係数が大きすぎた場合、閾値を0個にしてしまう副作用があります。一方、ペナルティ係数が小さすぎた場合、閾値の数が多くなり、過学習したモデルになってしまいます。そのため、適切なペナルティ係数を設定する必要があります。ペナルティ係数を利用せず、閾値の数を制限する定式化も可能ではありますが、決定変数の数が増え、必要となる量子ビット数が膨大になるため、そのような表現は利用していません。
補足ですが、上記のような式で表現した場合は必ずしも閾値が1個になるわけでなく、精度が大きく向上できる場合には閾値を複数採用することがあります。これは前述の通り過学習を引き起こす可能性もありますが、一方従来の決定木モデルでは発見しづらかった分岐を発見して、モデル精度が向上する可能性があります。例えば、ある特徴量の値に平均値から離れているほど分類結果が異なるという傾向が隠れていた場合、従来手法では発見しづらいですが、本研究の提案手法では十分に発見できる可能性があります。
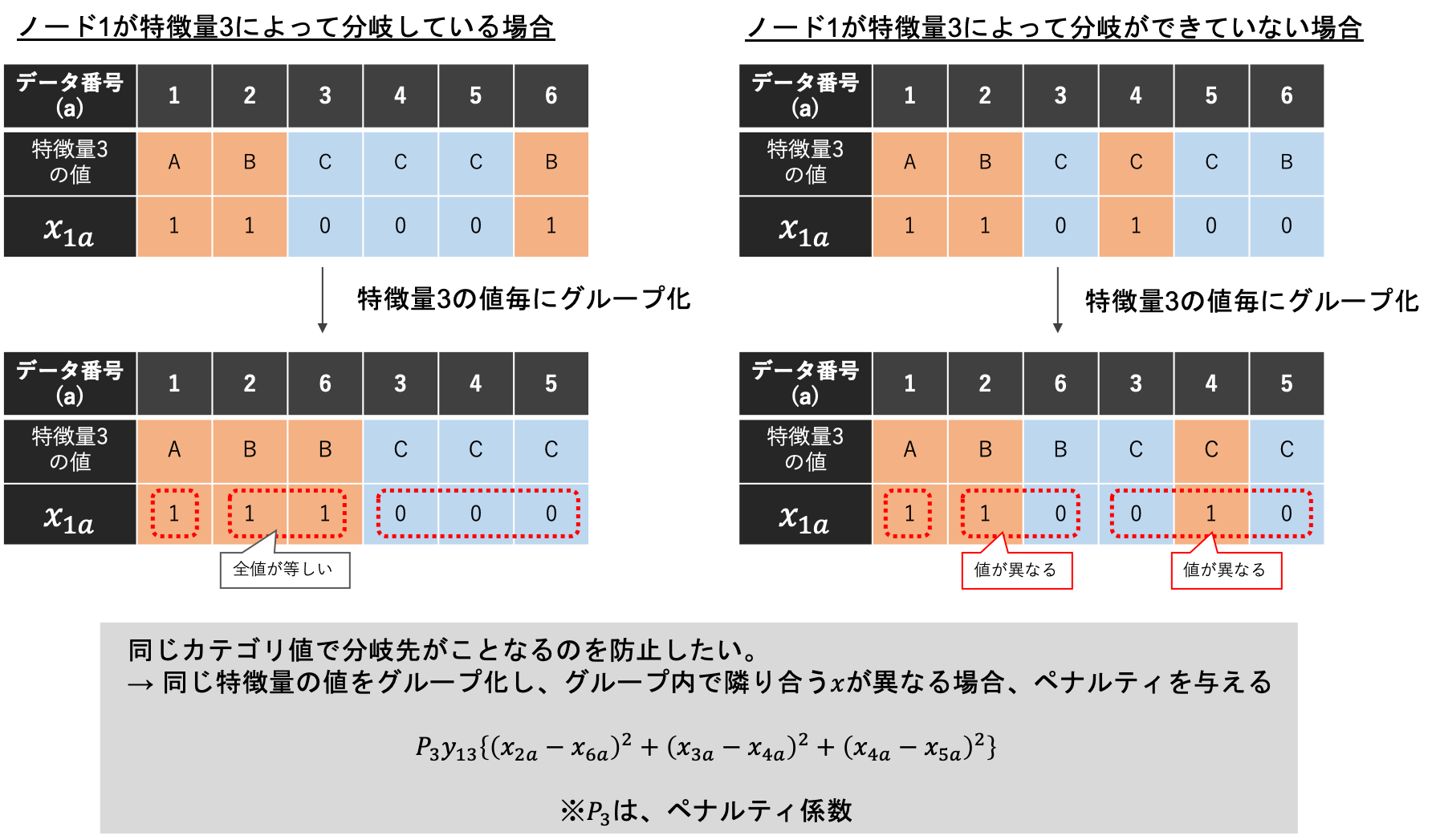
次に、最上部のノードの分岐基準の特徴量がカテゴリ型の場合に関して説明します。決定木モデルでは、分岐基準の特徴量の値が同じものは同じ分岐先になる必要があります。下図においては、図の左側が正しい分岐であり、図の右側が間違えた分岐になっています。正しい分岐になるようにするには、分岐基準の特徴量の値が同じ値をもつデータの分岐が異なる時にペナルティをかける必要があります。そこで、下図の下部のように、「ある特徴量の値が同じ値でグループ化したグループ内の決定変数$x _{na}$が異なり、さらにある特徴量が選択された場合」にペナルティがかかる式を準備しました。この式が、グループ内の全ての組み合わせに対してではないのは、同グループに所属する決定変数が多い場合だと決定変数の組み合わせが膨大となり、計算負荷がかかるからです。また、ペナルティ係数を十分に大きな値にすれば、グループ内の全ての組み合わせでなくても、正しい分岐になるからです。
補足ですが、一般的な決定木モデルでは、1つのカテゴリ値とそれ以外のカテゴリ値を分岐するというパターンしか考慮していないことも多いです。これは、各カテゴリ値の分岐を考慮すると2の(カテゴリ値の種類数 - 1)乗のパターン数を考慮する必要があり、カテゴリ値の種類数が多いと計算が重くなりやすいからです。しかし、本研究の提案手法の場合、カテゴリ値の各値の分岐先を学習時に考慮することができ、モデル精度が向上する可能性があります。例えば、カテゴリ値が50種類あり、25種類ずつ分類傾向が異なる場合、従来手法では決定木の深さが25以上ある必要がありますが、本研究の提案手法では1階層で表現でき発見しやすいです。ただし、モデルの自由度が高くなるので、過学習になりやすいという傾向もあります。
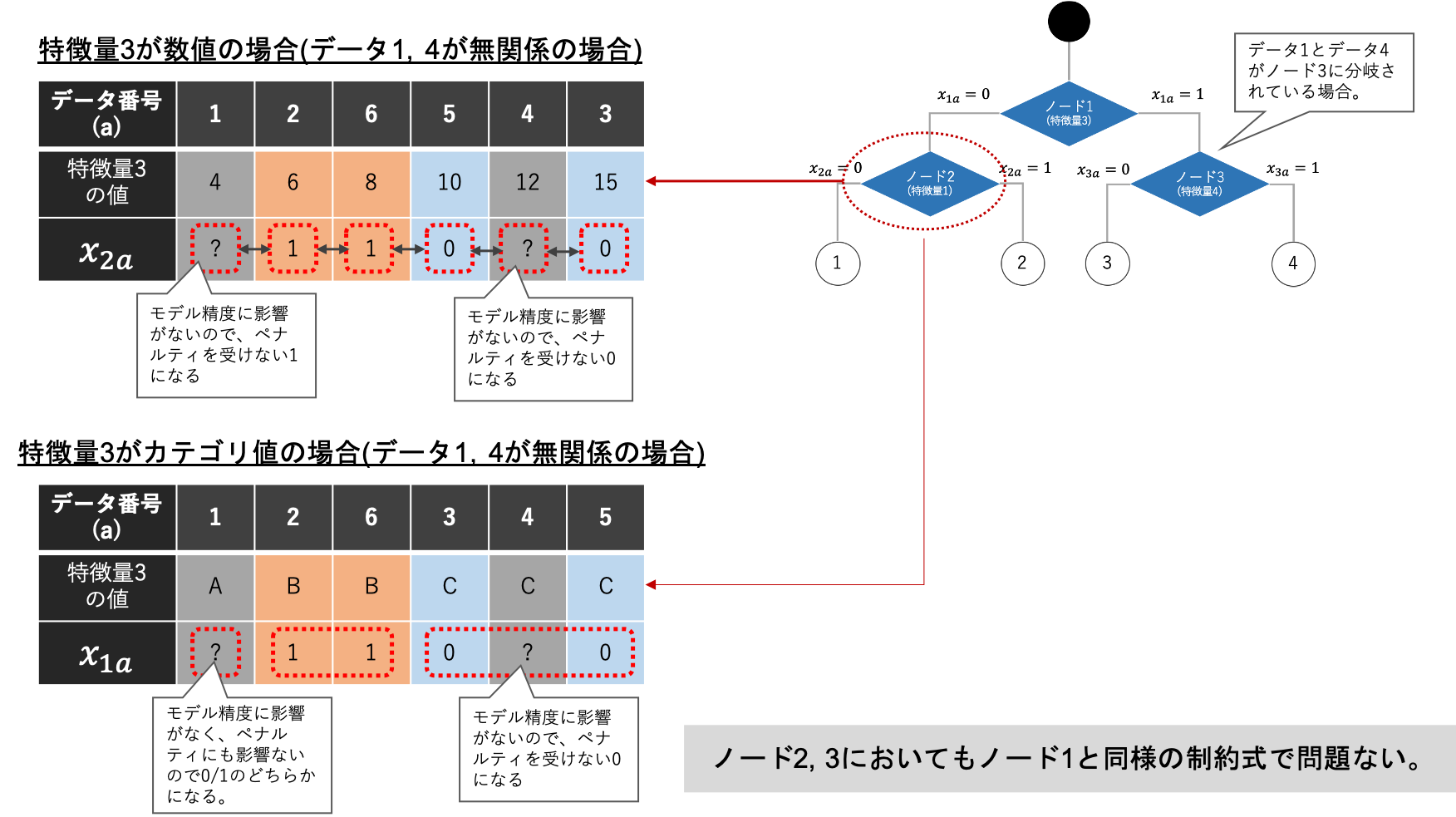
最後に、2階層目以降のノードの場合について説明します。結論から先に述べますと、最上部のノードのときと同様の式で表現して問題ありません。下図のように、2階層目のノードの場合、一部の決定変数$x _{na}$は分岐に関与しない決定変数です。そのためペナルティを受けないような値をとるように最適化されていきます。その結果、悪影響を与えず、さらに「分岐に関与する決定変数」が「分岐に関与しない決定変数」によって分断されても「分岐に関与しない決定変数」を通して制約を伝搬してくれるため問題ありません。
補足ですが、上記の説明から2階層目の決定変数$x _{na}$の半分は分岐に関与しないことに気づき、無駄な決定変数を使っているのではないか?と疑問を持たれている方もいると思います。そのご指摘は正しく、実は2階層目の決定変数$x _{na}$を提案手法の半分で表現することは可能です。ただし、そのような表現をすると式の次数が大きくなってしまう問題があります。結果として、必要な量子ビットの数が元の数より膨大になってしまうため本研究ではあえて冗長な定式化をしています。
モデルの分類精度に関する式
より良い決定木モデルを学習するためには、モデルの分類精度を式で表現し、それらを改善するようなモデルを探索させる必要があります。モデルの分類精度の式は、様々な表現方法がありますが、2分類問題であれば、各末端のノード(リーフ)のデータ数・教師値/予測対象値がTrue/Falseの数が準備できればおおよそ表現することができます。
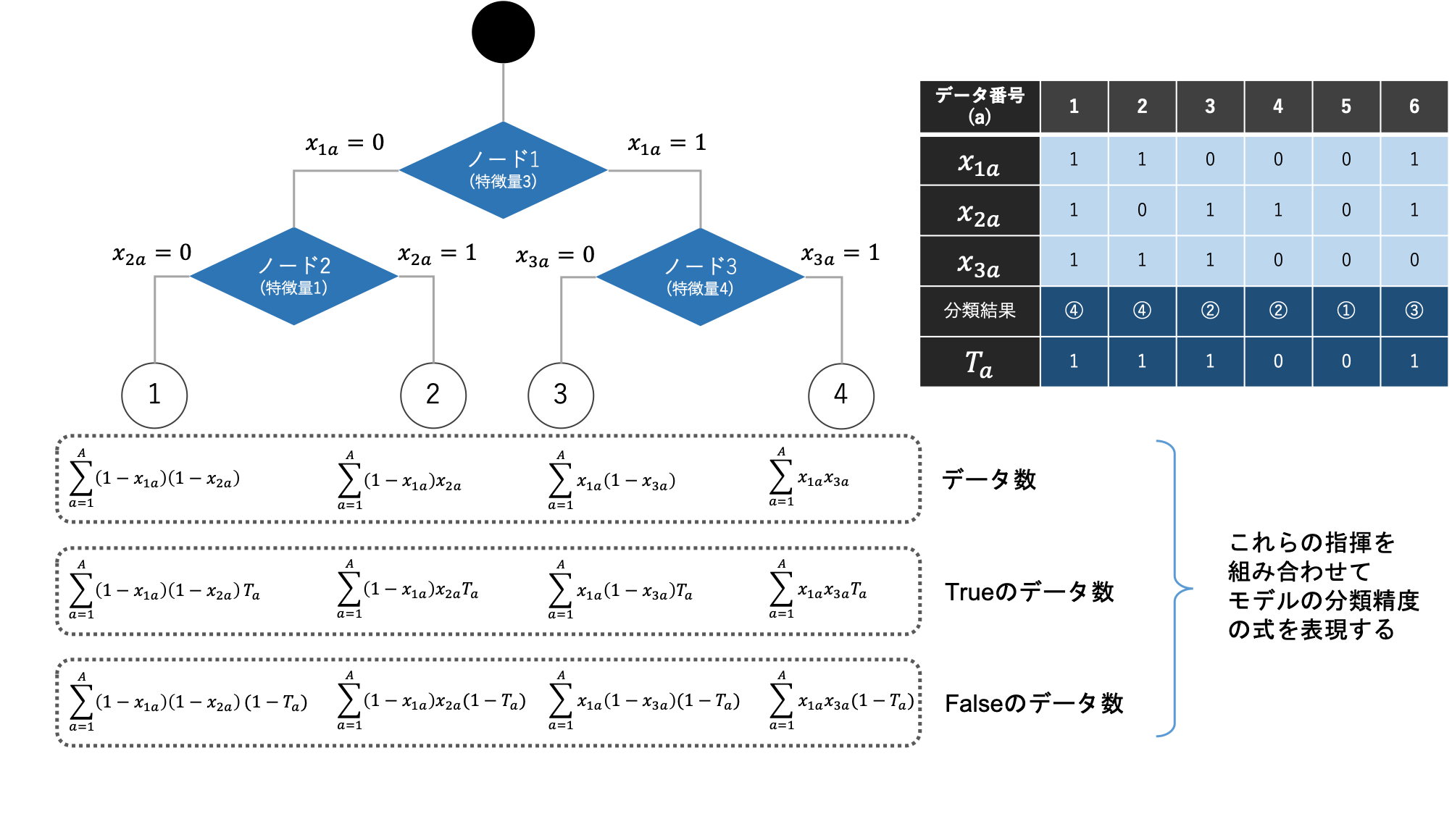
多くの決定木モデルでは、ジニ不純度やエントロピーが学習時のモデルの分類精度して採用されており、多くの現実の問題でも有効であることが示されてきました。本研究でもこれらの式の採用を目指します。しかし、QUBOにおいてジニ不純度やエントロピーの式そのものを表現することはできません。なぜなら、QUBOでは決定変数の割算や対数といった表現を利用できないからです。そのため、QUBO形式でジニ不純度やエントロピーの式を近似的に表現することを本研究では目指しました。最終的には下記のような式を採用しました。

上記の式について詳しく説明します。まずベースとして、モデルの分類性能を高めるために各リーフに分類された予測変数がTrueのデータ数とFalseのデータ数の差を最大化するようなモデルになるように、各リーフのTrueのデータ数とFalseのデータ数の差の2乗の式を準備しました。次に、学習データのTrueとFalseの数がアンバランスの場合でも問題内容にするため正規化を行い、データ数基準から学習データ全体のTrue/Falseを占める割合基準に変更しました。
定式化まとめ
以上のように4つのパートに分けて定式化を説明しましたが、まとめると下記のような定式化になりました。
- 定式化
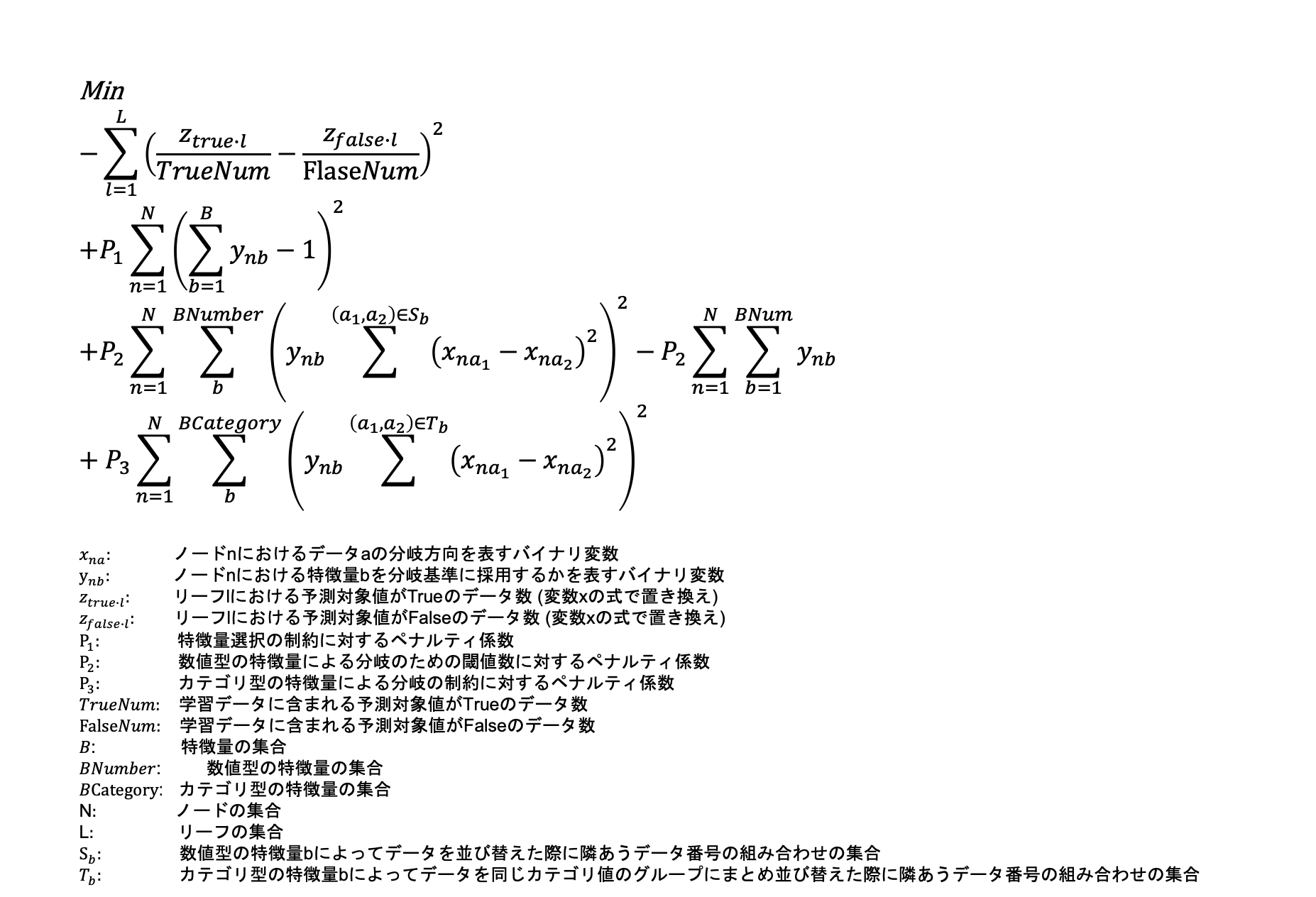
- 決定変数zの展開

イジングマシンを用いた2階層同時に学習する決定木モデルの精度はいかに?
では、実際にイジングマシンを用いた2階層同時に学習する決定木モデルが期待通りの働きをするか検証します。本研究はまだまだ検証中ですが、今回は一部の簡単な検証結果を紹介します。
検証用のマシンには、イジングマシンである富士通デジタルアニーラ(FDA)を利用しました。さらに、FDAから得られた解が局所最適化に達していない場合には、ヒューリスティックスな手法で局所解まで改善しました。
検証のデータセットには、2分類問題で2階層同時に学習する決定木モデルによって精度が向上した”nomao”,“wdbc”を選択しました。ただし、富士通デジタルアニーラで使用可能な8192ビットで問題を表現するには、学習データ数を100件程度にする必要があるため、各データセットからデータを150件ランダムサンプリングし、交差数3の交差検証によってモデルの精度を比較しました。
比較手法として、sklearn.treeのDecisionTreeClassifierを採用しました。パラメータは、決定木の最大深さ(max_depth)を2とし、その他のパラメータはデフォルトです。イジングマシンを用いた決定木モデルのカテゴリ型特徴量や特徴量選択に関するペナルティ係数は十分に大きな数字を設定し、数値型特徴量に関するペナルティ係数は0.04, 0.12, 0.24の3種類を準備し、最も良い精度のものを選択しました。決定木の最大深さは、同様に2としました。
| データセット名 | 手法 | Train AUC | Test AUC |
|---|---|---|---|
| nomao | 決定木 | 0.9601 | 0.8753 |
| nomao | イジングマシンを用いた決定木モデル (数値型特徴量に関するペナルティ係数:0.12) |
0.6987 | 0.7326 |
| wdbc | 決定木 | 0.9812 | 0.8994 |
| wdbc | イジングマシンを用いた決定木モデル (数値型特徴量に関するペナルティ係数:0.12) |
0.8721 | 0.7509 |
上記が、検証結果です。検証結果から、いずれのデータセットにおいても比較手法の決定木モデルより良い結果が得られていないことがわかります。またイジングマシンを用いた決定木モデルの学習データにおける精度が異常に高いという傾向もないので、過学習による精度悪化ではないことがわかります。
精度が予想より悪かった原因として以下のような理由が考えられます。 - イジングマシンが十分に良い解を見つかられなかった。 - 定式化のモデルの分類精度に関する式が既存手法のジニ不純度と比較し、悪かった。 - 有効な特徴量組み合わせを探索しているが、データ数が少なく有効であることを学習データからは見分けられなかった。
上記の原因の切り分けは、既存の決定木を「ジニ不純度基準」から「提案手法の分類精度に関する式基準」に変更しモデル精度の変化を確かめたり、データ数を変更しながら「決定木モデル」と「2階層同時に学習する決定木モデル」のモデル精度の変化を確かめることで、ある程度はできると思われます。原因がわかれば、提案手法のどこを改善していけばいいのか明確になり、さらなる改善もできるかもしれません。現状では十分な検証ができていないため、これらの結果は論文発表をする際には皆様に公表したいと思います。
まとめ
本研究はまだまだ論文にまとめるには十分な検証ができていませんが、イジングマシンや量子アニーラーによる機械学習の進化の可能性の一片を皆様に紹介できていれば幸いです。現状ではまだ実用レベルには至らないですが、近い将来には単体のモデルとして活用する他にも、アンサンブル学習モデルのベースとして採用し量子アニーラーに埋め込める問題サイズにしながら活用できる可能性はあります。引き続き、我々は近い将来の量子アニーラーの可能性を見極めながら応用研究を続けていきたいと思います。
広告
RCOでは一緒に働いてくれる優秀なエンジニアを募集しています。
TAGS :
#データ分析ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)