AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
こんにちは。今年2018年4月より新卒でRCOに入社した松田です。
kaggle というデータ分析のコンペティション運営サイトが流行っていますが、 RCOでも「kaggle部」という形で積極的に参加しています。
今回私は TalkingData AdTracking Fraud Detection Challenge というコンペティションに参加したので、そこで得た知見を共有したいと思います。
図: kaggleのサイト( https://www.kaggle.com/c/talkingdata-adtracking-fraud-detection/ )より
手前味噌ですが割りと初心者の私でもGWを犠牲に割りと好成績を出せたので、そのための勉強法やタイムラインを別記事 「kaggle初心者の私が3ヶ月でソロゴールドを獲得した方法」 にまとめました。宜しければ合わせて御覧ください。
この記事ではコンペの概要と解法をまとめることでkaggleで上位入賞するための具体的なテクニックを紹介できればと思います。
kaggle未経験者にもコンペの雰囲気がなるべく伝わるように書いたつもりなので、多くの方のお役に立てば幸いです。
コンペの概要
TalkingDataという中国のビッグデータサービスプラットフォームが持ってるクリックデータにおいて、ユーザーがモバイルアプリの広告をクリックした後ダウンロードするかどうかを予測するのが目的です。
90%はボットなどによるクリックでアプリのダウンロードを行わない不正(Fraud)なものらしく、それを検出したいというモチベーションなのでFraud Detection Challengeと名付けたっぽいです。
以下与えられたデータを少し詳しく見ていきます。
デカすぎるデータセット
訓練データとテストデータは以下のようになっています。
| ファイル名 | データ件数 | サイズ(zip解凍後) | クリック時刻の範囲 |
|---|---|---|---|
| train.csv | 184,903,890 | 7.54GB | 2017/11/6 14:32:21 ~ 2017/11/9 16:00:00 |
| train_sample.csv | 100,000 | 4.1MB | trainの一部 |
| test_supplement.csv | 57,537,505 | 2.67GB | 2017/11/9 16:00:00 ~ 2017/11/10 16:00:00 |
| test.csv | 18,790,469 | 863MB | test_supplementの一部 |
なんと件数が1億を超えるデータであり、それをいかに扱うかがこのコンペの肝と言えます。
予測を提出するのはtest.csvについてのみでよく、クリック時刻の範囲は2017/11/10のおよそ4時~6時、9時~11時、13時~15時の3つのセクションで構成されています。 test_supplement.csvはどうやら運営が間違えて公開してしまったらしいのですが、これがないと後で説明する特徴量が正しく作れないので利用するのが基本となります。
無味乾燥な説明変数
まず訓練データの一部の行を見てみましょう。
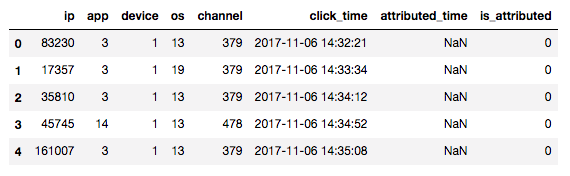
まずは説明変数から見ていくと、
| カラム名 | 意味 | 種類 | 例(筆者の想像) |
|---|---|---|---|
| ip | ユーザーのIPアドレス | 110116 | 192.168.0.1 |
| app | 広告が宣伝するモバイルアプリ | 348 | パズルクエスト |
| device | ユーザーの端末 | 749 | iPhone7 |
| os | ユーザーのOS (versionも区別) | 244 | iOS 11.3.1 |
| channel | 広告媒体のチャネル | 177 | ラッキーニュース |
| click_time | 広告がクリックされた時刻(UTC) | - | - |
のようになっています。
click_time以外はカテゴリカルデータで、始めから整数で表現(Label Encoding)されたものが与えられています。 これはデータとしては非常にシンプルでここからいかに情報を引き出すかがポイントとなります。
アンバランスな目的変数
以上を用いて予測する対象がis_attributedというアプリダウンロード有無の指標です。 is_attributedが1のデータは広告クリック後にアプリがダウンロードされたクリックイベント、0のデータはそうでないものです。
約1.8億件の訓練データ全体に対してis_attributed=1のデータは50万件弱で、割合にして約0.2%と非常に少ないです。
このように、目的変数の分布がアンバランスであることがこのコンペの特徴のひとつです。
ちなみにアプリがダウンロードされた時刻attributed_timeも与えられていますが、活用するのは難しいので無視して構いません。
基本的な解法
まずは基本的な解法を説明します。 それは私が取り組み始めたコンペ終了約2週間前の時点では既にKernelやDiscussion(kaggleサイト上でコンペのcodeや知見を共有する場所)で公開されていたものです。
一言で言うと「カテゴリー変数を組み合わせて特徴量を量産してLightGBMにぶち込む」です。 以下詳しく見ていきます。
特徴量エンジニアリング
まずは作成する特徴量を順番に見ていきましょう。 実際の作業時間の大部分は特徴量の試行錯誤です。
count系
一種類目が各カテゴリーのデータ全体での登場回数です。
例えばipの登場回数からip_countという新しい特徴量を以下のように作れます。
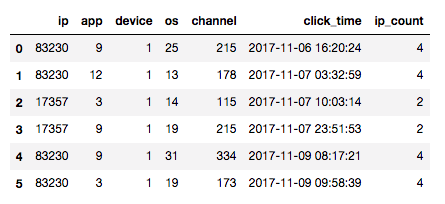
図: 一部のデータを使って例示。ip=83230のデータは4つあるのでip_countが4、ip=17357は2回なので2となっている。
更にこれはカテゴリーの組み合わせでもよいので色んな種類が作れます。 例えばipとappの組み合わせが等しいものの登場回数からip_app_countという特徴量を作れます。
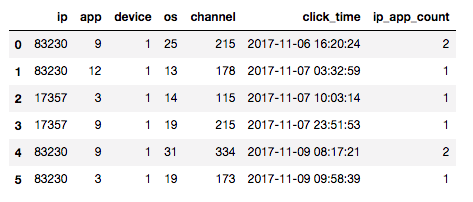
図: ipが83230でappが9のものは2つあるのでip_app_countが2、それ以外は1つしかないのでip_app_countは1となる。
組み合わせのうちKernelやDiscussionでよく使われていたのは以下の通りです:
- ip, app
- ip, device
- app, channel
- ip, app, device
- os, app, channel
- ip, day, hour (hourはclick_timeから作る)
count unique系
上記count系からすぐに思いつくのがcount unique系です。 例えば一つのipがいくつのappを持っているかを表すapp_by_ip_countuniqという特徴量を以下のように作れます。
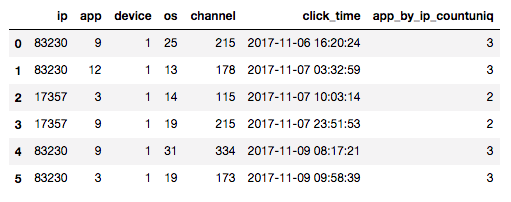
図: ipが83230のデータはappが9, 12, 9, 3と3種類あるのでapp_by_ip_countuniqが3となる。
これも組み合わせとして多くの可能性があり、特に以下のようなものが使われていました:
- app_by_ip_countuniq
- device_by_ip_countuniq
- channel_by_ip_countuniq
- app_by_ip_device_os_countuniq
- channel_by_app_countuniq
next click系
あるカテゴリーについて次のクリックまでの時間を特徴量として利用することが出来ます。 例えばipについてまとめてip_next_clickを作成すると以下のようになります。
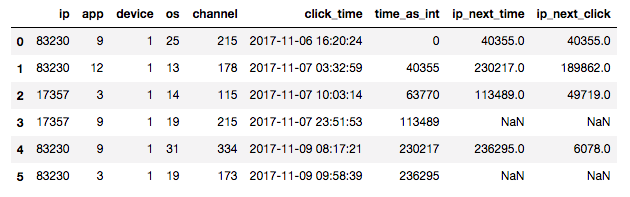
図: time_as_intはclick_timeを適当な整数にしたもの、ip_next_timeは同じipの次のデータのtime_as_int。その差分で各ipにおける次のクリックまでの時間ip_next_clickが作れる。各ipの最後のデータはip_next_time, ip_next_clickが欠損データ(NaN)になってしまうので学習時には適当に大きな値を入れておく。
上の例ではipについてまとめましたが、まとめ方はいろいろ可能で特にip, os, device, appの組が良く使われていました。
Kernelで明記してるものは見かけませんでしたが、test_supplement.csvを使わないとtest.csvに対して正しくnext clickを生成出来ないので注意です(test.csvはデータが時間的に連続じゃないので)。
またprevious clickを作れますがnext clickの方が予言力は高いです。
next clickは未来の情報を用いて特徴量を作成してるので実際のシステムには実装できないのですが、今回のコンペではこれが強力な特徴量だったので私の知る限り全ての参加者が利用してました。
target encoding系
目的変数(target variable, 今回はis_attributed)の情報を利用してカテゴリー変数を変換する方法をtarget encodingといい、今回も少し効きます。
例えば以下のようにis_attributedが与えられたとして、ipについてis_attributedの平均を取ることでip_target_encを作成することが出来ます。
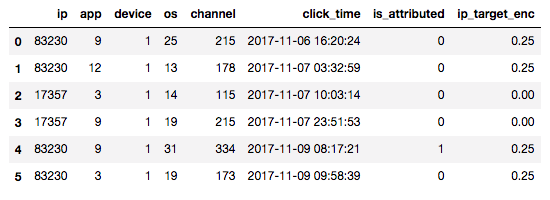
図: ip=83230は4つあってそのうち1つがis_attributed=1なのでip_target_enc=0.25となる。
上図は(仮想の)訓練データですが、テストデータに対しては訓練データで計算したターゲットの平均を割り当てるだけです。
ただしこれだと予測時には得られないデータを訓練に用いているため実践時の精度が落ちるリークという問題をもろに起こしています。
そこである行のtarget_encの値を計算するときはその行のデータ以外で計算するLeave One Out(LOO)という手法をとると次のようになります。
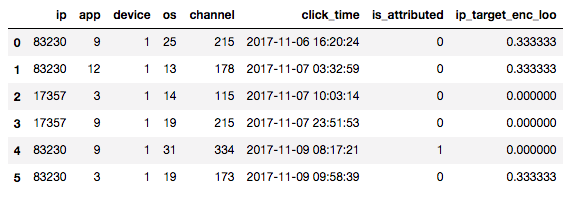
図: ip=83230でis_attributed=0の行は自分以外に3つ同じipがあって一つがis_attributed=1なのでip_target_enc_looが1/3=0.333..となる。
ところがこれはこれで同じipのものについて注目してみると、targetであるis_attributedとip_target_enc_looが1対1対応してしまっている(例えばip=83230においてis_attributed=0,1 <-> ip_target_enc_loo=1⁄3, 0)ので結局リークしてしまいます。
そこで両者の中間をとって、学習データを予めn個の塊に分割して一つの塊で平均を計算するときは自分以外の塊を使って計算する手法をとるのがよくやる方法です。
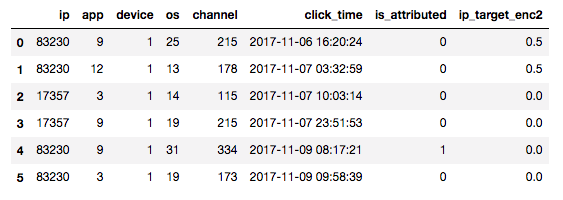
図: 簡単のため2分割の場合。実際は4,5分割くらいが良い。上半分のデータについてip_target_enc2を計算するときは下半分の平均をとっている。逆もしかり。
更に今回は時系列データであるためテストデータにおけるtarget_encと訓練データのそれに質的な差が出ないように、訓練データのtarget_encを計算するときに自分より前のデータのみを用いてターゲットの平均を計算するのが良いです。
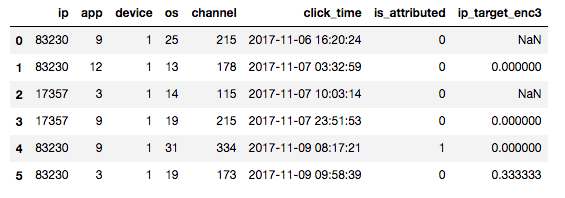
図: 各ipごとに自分より前のデータのis_attributedの平均がip_target_enc3。例えば最後の行はip=83230が今までに3回登場していてそのうち1つがis_attributed=1なのでip_target_enc3=0.333..となる。ipが初登場のときは欠損(NaN)だが適当に0とか全体の平均~0.002で埋めるとよい。
以上target encodingという手法による特徴量生成でしたが、特にipは種類が多い(10万以上)カテゴリー変数でそのまま使うと過学習を起こしてしまうのでcount系などと合わせてtarget encodingが効きます。
Validationを制する者がコンペを制す
重要なのが検証データ(Validation Data)の作り方です。
検証データとは過学習を防いだりモデルを訓練した後の答え合わせに使うために訓練データから一部を抜き出したデータですが、これが正しく無いと目が見えない状態でゴールに向かって歩くようなものなので非常に重要です。
正しい検証ができるように一般には「訓練データと検証データの関係 = 訓練+検証データとテストデータの関係」となるようにすべきです。
今回のデータは時系列データなので検証データとしては訓練データの中で新しい方の2~3割(例えば11/9のデータ)を取ってくるのが無難でしょう。
機械学習モデル
使うモデルはLightGBMです。 これはMicrosoft社が作った決定木ベースの学習アルゴリズムで、速いし省メモリだし精度も汎用性も高いので現在kaggleのコンペで鉄板になっています。
上で作った特徴量たちをこれにぶち込むだけです。
アルゴリズムを理解してデータに応じてパラメータを調整すべきですが、その説明は今回割愛します。
基本解法まとめ
以上のことはほとんどKernelの知識の寄せ集めでそれをやるだけでシルバーメダル圏内のスコアを出すことが出来ます。
ただし今回のコンペはデータ量が多く全データを用いて計算を実行すること自体のハードルが高かったのだと思います。 実際これを実行するためにはメモリ50GB以上のマシンが必要なので、手元にハイスペックマシンがあるか少なくとも数千円は気にせずクラウドを使いこなさなければいけません。
上位陣の解法は?
さてスタンダードな解法を見てきましたが、上位陣はいったいここからどのような工夫をしてスコアを伸ばしたのでしょうか?
有り難いことにこのコンペではほとんどの上位陣が解法を比較的詳しく公開してくれているので、勝手ながらそこから得られた知見をまとめさせていただきます。
思いの外長くなってしまったので 別記事 にしました。 よろしければ引き続き御覧ください。
広告
RCOアドテク部では優秀なエンジニアを募集しています。
TAGS :
#データ分析ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)