AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
こんにちは。今年2018年4月より新卒でRCOに入社した松田です。
さて 前回の記事 で kaggle の TalkingData AdTracking Fraud Detection Challenge の基本的解法を見てきましたが、 この記事はその続きで上位陣たちが公開して下さった解法を勝手ながらまとめます。
上位陣の解法
まず以下がkaggleのサイトにある上位陣の解法リンク&それに対するちょっとしたコメントです。
- 1位のチーム
- 2位のチーム
- 3位: bestfittingさん
- 2018年6月現在kaggleの総合ランキング1位の人によるNeural Networkメインの解法
- kaggle公式のインタビュー記事で一般的なkaggleに関する知見を共有してくれている
- mamasinkgsさん
- 特徴量を最も多く使った解法
- CPMCさん
- 解説が丁寧でコメントも多い
- tkm2261さん
- ソースコードも動画解説もある
- BigQueryを使ってSQLによる前処理をした解法
- Alberto Daneseさん
- publicからprivateの伸びがすごい
- データを注意深く使っていてその姿勢は真似たい
注: たまたま個人的に印象に残ったもので網羅性は保証できません
これらの解法と前記事のスタンダードな解法の差分をまとめさせていただきました。
もはや常識 random seed average
予測モデルを複数作ってそれらの平均を最終的な予測とするensembleという手法がkaggleでは常識となっています。 配合して強くしてくイメージですね。
配合する際はなるべく強いモデルをなるべく多様性があるように複数作らなければなりません。
当然それは大変なことでだからこそkaggleのコンペはチームを組んだほうが有利なのですが、お手軽な手法としてrandom seed averageといういうのがあります。 それは、モデルを訓練する際にランダム性がある場合にランダムシード値を変えて複数モデルを作りそれの単純平均をとるというものです。 アイデアも実装も非常に簡単なのですがスコアがほぼ確実に伸びるので、もはやこれをするのがデフォルトみたいになっていて今回のコンペでも活用されたようです。 (なのでこの項目は基本的解法に含めるべきかもしれません。)
更にはランダムシード値だけでなく訓練時のハイパーパラメターを変えたモデルを配合することでより多様性を加えることもできます (私は今回それをやりました)。
更には複数のモデルの予測値を説明変数としてそれらをまとめる学習モデルを組むstackingと呼ばれる手法もあります。 しかしモデルの予測値は正解データの情報を含んでいるため広義のtarget encodingだといえリークする可能性があるので使いこなすのは難しいそうです。 今回のコンペでstackingによってスコアを上げたという報告で目立ったものはは私の知る限りありませんでした。
力技で特徴量生成
カテゴリー変数はip, app, channel, os, deviceの5種類あるのでこれらの組み合わせは $2^5-1=31$ 通りあり、それぞれについてcount系、next click系など様々な特徴量が作成できます。 更にcountunique系は2つのグループを選抜する組み合わせなので $3^5-2\cdot (2^5-1)-1=180$ 通りあります。 更に更にここで紹介した以外にも日付時間も組み合わせたり、ランク、平均、分散を利用したり、組を作る時間を制限したり(例えば直近数時間でのipのcount、特に未来の情報を重視するとよく効くそうです)することもできます。 特に5位のチームのmamasinkgsさんは7000以上の特徴量を生成したとのことで、シンプルな元データからそこまで作れるのかと感心しました。
ナイーブに考えるとこれらのうちどれを使うか真面目に考えないといけなそうですが、どうやら経験的にLightGBMは弱い特徴量を入れても学習に時間がかかるだけで予測性能が下がることは無いそうです。 それを利用して上位陣の多くは数百の特徴量をLightGBMにぶち込むことでスコアを上げていったようです。
しかしただでさえデータ量が1億件あるので特徴量を増やしていくと計算コスト(お金も時間も)が更に膨れ上がってしまいます。 仮にお金に糸目を付けないとしても数千もの特徴量を全部使うのは難しく結局特徴量を取捨選択しないといけないのですが、そのためには実際試してみるしかなく結局かなりのお金と時間がかかります。
しかし次のDown Samplingという手法でこの問題をかなり緩和することができ、特に1位と2位のチームはそれをうまく活用していたようです。
マジか早く教えてよ Negative Down Sampling
今回データは多いといえど、目的変数がアンバランスでis_attributed=1のpositiveデータは0.2%しかありません。 ということは99.8%のis_attributed=0であるnegativeデータはあまり学習に重要ではないので、ほとんどを捨てることで計算を楽にしちゃおうというのがNegative Down Samplingです。
重要度が低いとはいえデータ量を少なくしたらスコアが下がりそうですが、1位の方のレポートによるとあまりスコアは下がらず、むしろ取ってくるsampleを変えて学習したモデル組み合わせることでスコアが上がるそうです。
この手法により計算に必要なメモリも時間も大幅に下がるのでより多くの特徴量を加えることができるだけでなく試行錯誤のスピードも早くなり、優勝チームはこれが大きな勝因と言っていました。
俺もやりたかった トピックモデルの応用
これは優勝チームとCPMCさんが使ったテクニックですが、少し込み入っているので具体例と共に軽く解説します。
文章データの例の方がわかりやすいのでまず以下のデータを考えてみましょう。
| 文章1 | “I like driving cars. Cars are great.” |
| 文章2 | “I drive a car everyday. Driving is the key to my health.” |
| 文章3 | “I like singing songs. Music is my life.” |
| 文章4 | “Just because I love music doesn’t mean I am good at singing.” |
| 文章5 | “Singing songs while driving is awesome.” |
この各文章に対して各単語の出現回数のカラム(Bag of Words)を作るのが自然言語処理の定石です。
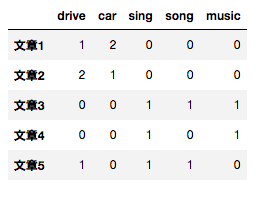
このままでも良いのですが文章が多くなると数万数十万の単語が出てきてしまうので、この行列を特異値分解(SVD=Singular Value Decomposition)することで以下のような行列を得られます。
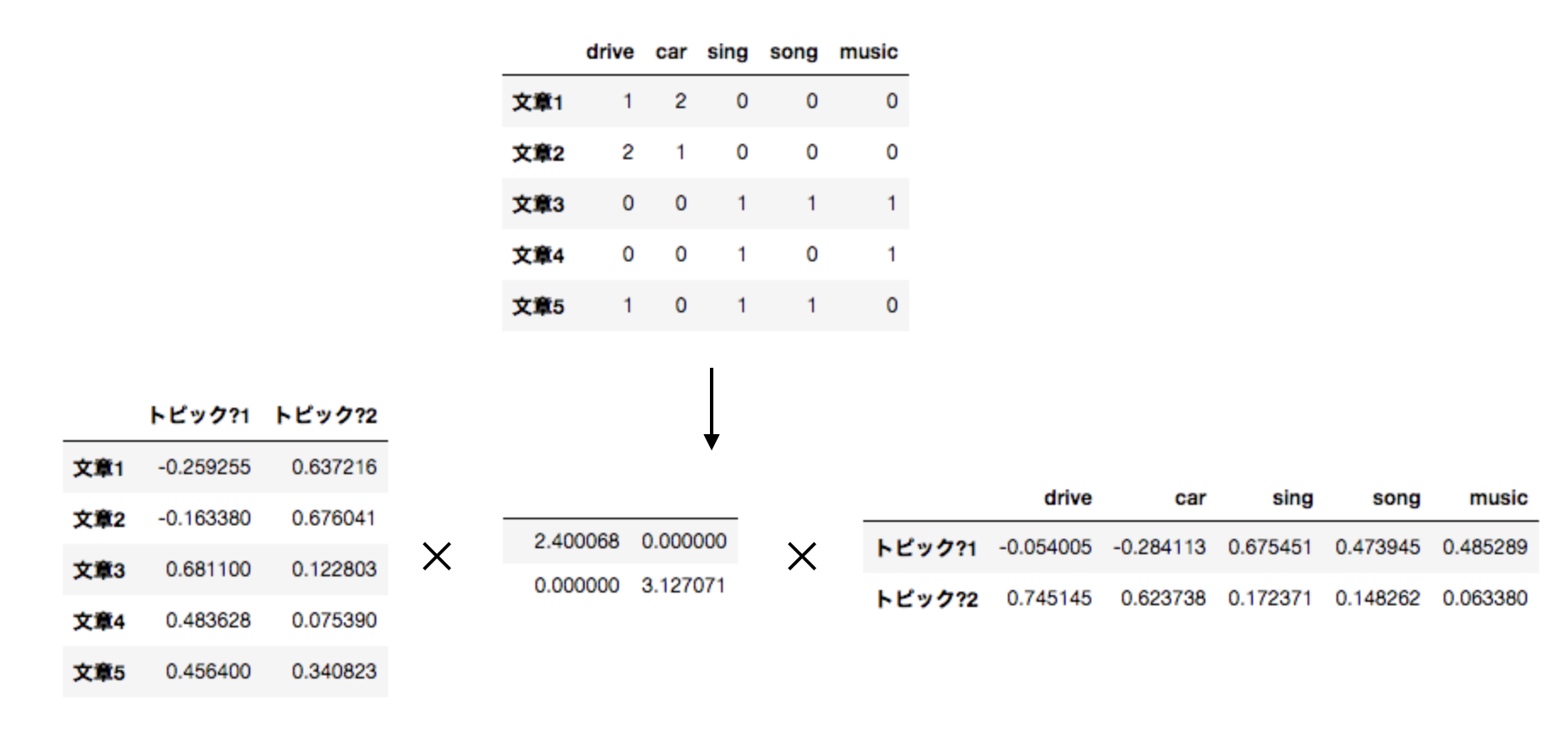
ここではランク2に分解してみました。 特に一番左の行列は元のデータの特徴量(=Bag of Words)を次元削減したものとして各文章の特徴量として使えそうです。 カラム名をトピック?としましたが、トピック?1は音楽系、トピック?2は車系を表す特徴量と解釈できそうだからです。 しかし”?“を付けたのはあくまでも特異値分解をして得られた行列の一つであり、各文章のトピックをよく表しているとは限らないからです。例えばマイナスの値を取るのもよくわからないですし、トピック?1とトピック?2は直行したベクトルですが文章5のように車も音楽も表す文章はあるのでそこをうまく表現できてなさそうです。
そこではじめから各文章が背後にいくつかのトピックを持っていてそのトピックに基いて単語が現れると仮定して確率モデルを作り(トピックモデル)、各文章が各トピックから来ている確率を推定することで次のように特徴量を作れます。
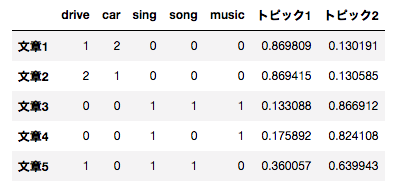
図: 背後のトピック数が2と仮定した場合。ここではLDAというアルゴリズムを用いた。 (トピックが選ばれる事前確率分布としてDirichlet分布を用いているので、潜在(Latent)トピック空間にDirichlet分布を用いてデータを割り当てる(Allocation)アルゴリズムということでLDAと呼びます。) さきほどのSVDの場合よりもトピック1, トピック2がそれぞれ車, 音楽トピックとしてしっくりきます。
さてこれを今回のコンペのデータに対してどのように応用出来るのでしょうか?
まず以下のようにどのipとどのappが共に発生したかを表す共起行列を作成します。
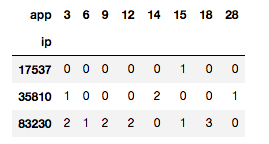
これに対して先程のようにSVDやLDAを適用することでipのappによる潜在トピックを特徴量に作ることができます。
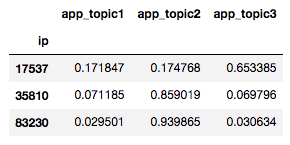
図: 先程の共起行列にトピック数3でLDAを用いた。これをipをkeyに元のデータセットに結合すればよい。
これも力技で作ろうとすると 180通り×トピック数 の特徴量が作れますが、CPMPさんは ip x app と (ip, device, os) x app の2種類についてトピック数 3~5 でSVDをやったそうです。
一方1位のチームはLDAを用いて(ip, app, device, os, channel)から2つを取った組み合わせ $5\times 4=20$ 通りについてトピック数5で100個の特徴量を作ったそうです。
トピック数はハイパーパラメターでありますが、両チームともそのtuningは特に行っておらず直感で決めたそうです。
私はコンペ中今回のデータにトピックモデルを活用できるとは思いつかなかったので差が開くのも納得です。 しかしこのように複数のカテゴリカル変数から共起行列を作って行列分解する方法は過去のコンペでもやられていて定石になってきてるっぽいです。 このように他者の解法から更に経験を学べるのがkaggleの良いところだと思います。
ちなみにLDAのアルゴリズムについては書籍 「トピックモデルによる統計的潜在意味解析」 の3章に詳しくまとまっており、1,2章も潜在トピックモデルについての考え方をとてもわかりやすくまとめています。 実際この記事の内容はこの本を参考にさせていただきました。
これぞ匠の技 Neural Network
これまでの解法は基本的にLightGBMを使うことを想定していますが、Neural Networkもやはり魅力的で多くの人が試したようです。 しかしNeural Networkの構成をデータに合わせて調整するのは非常に難しく、案の定多くの参加者はLightGBMでの精度にNeural Networkが敵うことなく多様性を増すためにensembleに加える程度という解法でした。
しかし、現在kaggle総合ランキング1位のbestfittingさんはなんと23個の特徴量とNeural Networkだけでゴールドメダル圏内に入るモデルを作れたそうです。 特徴量選定もさることながらNeural Networkをどうやって構成したのか非常に気になりますが、コメントによるとどうやら今まで論文で読んだり自分で試したモデルのストックが大量にあり、そこから問題設定が似てるのを参考にすることで多くの時間を節約できるっぽいです。 ストックがあるのもすごいしその経験があるからこそ調整も効率よく進むと思うので、今はひれ伏すしか無いと共に憧れます。
最後に
最後まで読んでいただきありがとうございました。 私は今回このコンペに参加して色々なことが学べたのでこの記事がそれを共有するのに少しでも役立てば幸いです。 また解法を公開して下さった方々に心から敬服・感謝いたします。
広告
RCOアドテク部では優秀なエンジニアを募集しています。
TAGS :
#データ分析ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)