AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
データ分析基盤チームでエンジニアをしている宮井です。
社内で使われている内製のデータ分析プラットフォーム「Crois」を開発しています。
今回はそのシステムの構成について解説していこうと思います。
システムの概要
Croisのメインとなる機能は機械学習向けジョブスケジューラーですが、単なるジョブスケジューラーとしてではなく、データを加工・整形するプラットフォームとして開発がスタートしました。
社内ではCroisをデータ・ソリューション・キッチンと位置づけています。 データを食材に見立てて、ITプランナー・データサイエンティスト・エンジニアが連携してデータを料理する場=キッチンということです。 三者がシェフとして料理に集中できるよう、他の作業を引き受けるのがCroisの役目です。
データを使った施策を行う上で三者にとっての課題は例えば以下のようなことがあります。
- ITプランナー
- データサイエンティストの作ったモデルを簡単に利用したい。
- 自由に定期実行などを設定したい。
- データサイエンティスト
- 対象の設定などのパラメータはITプランナーに任せたい。
- インフラやセキュリティの設定に時間をとられたくない。
- エンジニア
- 同じような設定を何度もしたくない。
- 適切なインフラを適切な権限で提供したい。
こういった課題を解決するシステムとしてCroisが開発されました。 構成としてはコンテナカタログ+ジョブスケジューラーという感じになっています。
共有・実行されるDockerコンテナはモジュールと呼んでおり、入出力のディレクトリやパラメータの受け渡しの仕方など一定のお作法に則って開発されたコンテナです。 そのコンテナを任意のタイミングで適切なインフラ・セキュリティで実行できます。
技術選択の背景
車輪の再発明にならないように、ジョブスケジューラー部分には既存のOSSを利用できないか検討していました。 求めていた機能としては以下の5点になります。
- 非エンジニアでも書けるように、ワークフローをYAMLやJSONなどで記述できること。
- 権限管理機能やコンテナカタログとの連携のためにジョブスケジューラーをラップする必要がある。そのためにAPIが公開されていること。
- グループ会社で横断して使うこともできるように高いスケーラビリティを持つこと。
- コンテナとの親和性が高いこと。
- 運用負荷が低いこと。
この要件に合うOSSのジョブスケジューラとして候補に上がったのはDigdagです。 DigdagはYAMLのようなシンタックスでワークフローを記述できますし、タスクの実行環境としてコンテナを指定することもできます。 またAgentモードで起動させるノードを増やすことでスケーラビリティも確保できます。 しかしAPIが正式には公開されていないため今後の仕様変更に追随するのが大変そうに思いました。
他の検討対象としてArgoも少し検討しました。 必要としている機能はほぼ満たしていたのですが、Croisを開発し始めた当時は社内にKubernetesの知見がなく、 Kubernetesクラスターの運用を含めた運用負荷が高くなりそうと思い、採用を見送りました。 最近ではKubernetesを使う案件も出てきており知見も貯まっていくことから、次期バージョンを作ることがあればぜひ使いたいと思っているOSSです。
そこで白羽の矢が立ったのがAWSのマネージドサービスであるStep FunctionsとAWS Batchを組み合わせた構成です。 Step FunctionsのJSONは人が書くには辛いシンタックスですが、そこはコンバーターを作ることで解決することにしました。 その点を除けば、すべての要件を満たしています。特にスケーラビリティと運用負荷の面では、これ以上の物はないと思います。 加えてIAM RoleとKMSキーをうまく組み合わせることで、セキュリティ面でもメリットがあることがわかりました。この点については後述します。
ワークフロー実行の流れ
ここからはCroisがワークフローをどのように処理しているかの流れを説明していきます。 まず最もシンプルなワークフローを見てみましょう。
tasks:
- name: task1
module: sleep
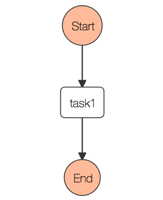
このワークフローはsleepというモジュールを実行するというだけのものです。
これを実行するとStep FunctionsのAmazonステート言語(ASL)のJSONへコンバートされます。
Step Functions上では以下のようなStateMachineになります。
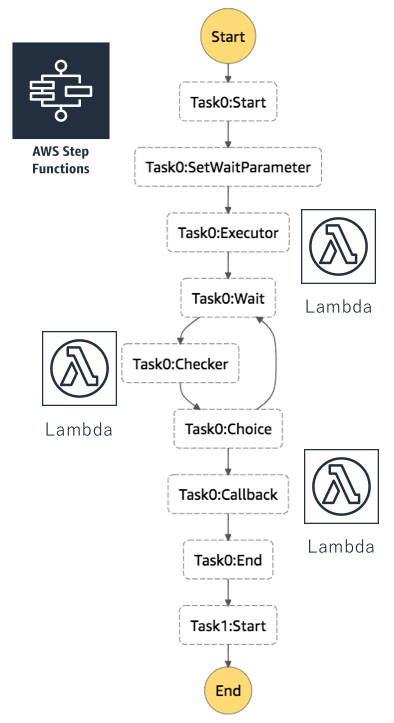
このStateMachineには3つのLambdaが含まれています。
上から順に1つ目がAWS BatchへジョブをsubmitするLambda(Task0:Executor)、
2つ目がジョブのポーリングを行うLambda(Task0:Checker)、
3つ目がジョブの成否判定を行うLambda(Task0:Callback)です。
各Lambdaを経由して以下のようにAWS Batch上でジョブが実行されます。

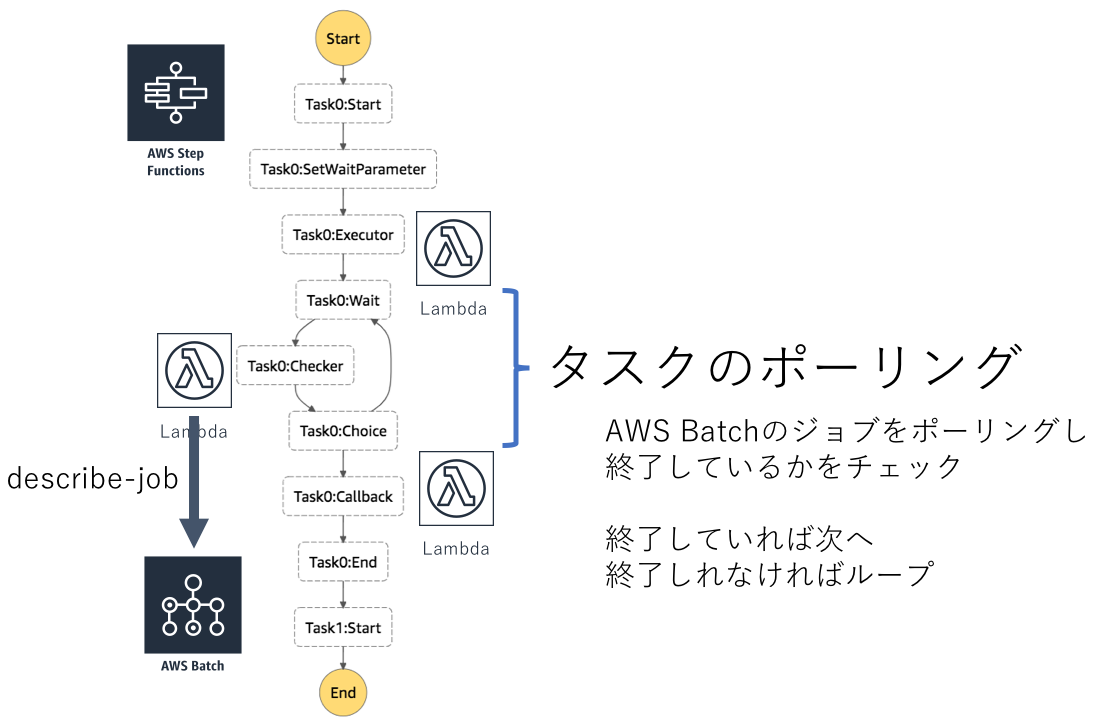
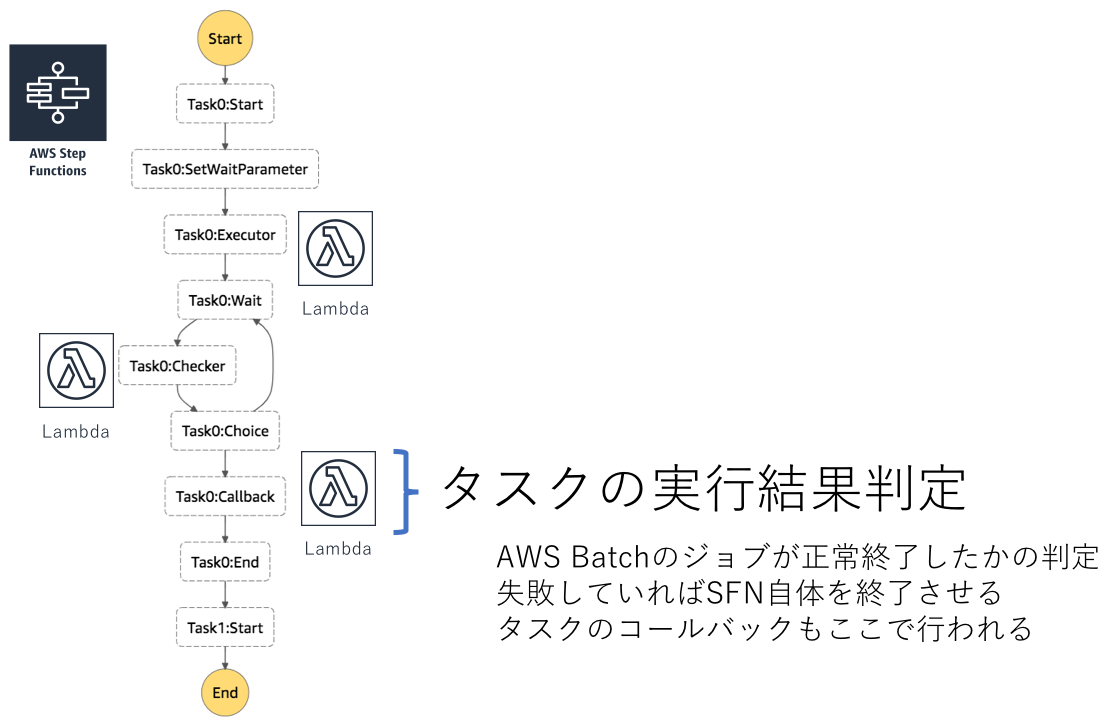
ワークフロー内のタスクが増えれば、その分だけ同じステップが増えていきます。
なお現在はStep Functionsから直接AWS Batchのジョブを実行できるため一部のLambdaは不要です。 開発した当時はその機能がなかったため、Lambdaを経由してAWS Batchのジョブを実行しています。
ワークフロー内では並列実行にも対応しています。
ワークフローの定義は以下のようなものになります。parallelフィールドに並列で実行したいタスクを書く形です。
tasks:
- name: task-1
module: sleep
- parallel:
- tasks:
- name: task-3
module: sleep
- tasks:
- name: task-4
module: sleep
- tasks:
- name: task-5
module: sleep
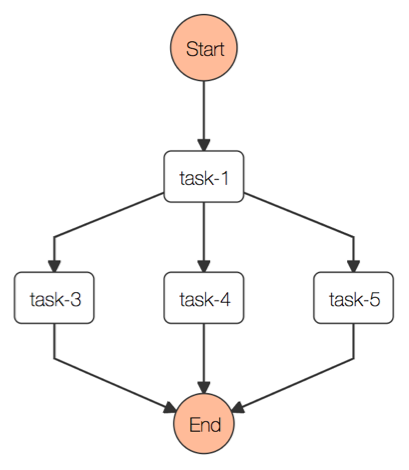
並列実行はStep FunctionsのParallel機能を利用して実現されています。 このワークフローのStateMachineの並列実行部分を抜き出したのが以下の図です。
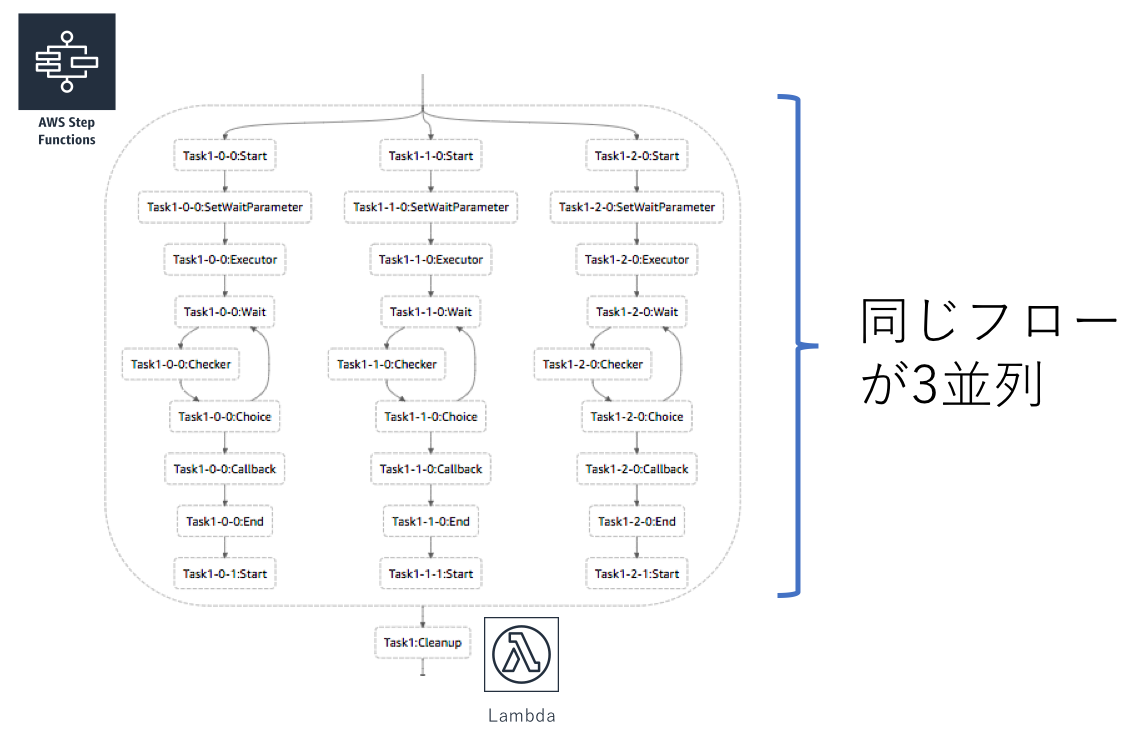
Parallel部分では先ほどのモジュールを実行するフローが並列で入っていることがわかります。
各Parallelで実行された結果が配列で返ってくるため、最後のLambdaの部分でそれをflattenしています。 そうすることで直列のタスクと並列のタスクを同じように次のタスクで扱うことができます。
次にAWS Batchで実行されるコンテナ内での処理フローについて説明します。
ワークフロー内のタスクとしてコンテナを実行する場合、前のタスクで出力したデータを使ったり、保存された秘匿情報を受け渡す仕組みが必要となります。 それらを実現するために、実行されるコンテナに外部からエージェントを入れる仕組みが実装されています。 エージェントがそれらの処理を受け持つことで、モジュールはローカルにあるデータのみを扱えば良いようになっています。
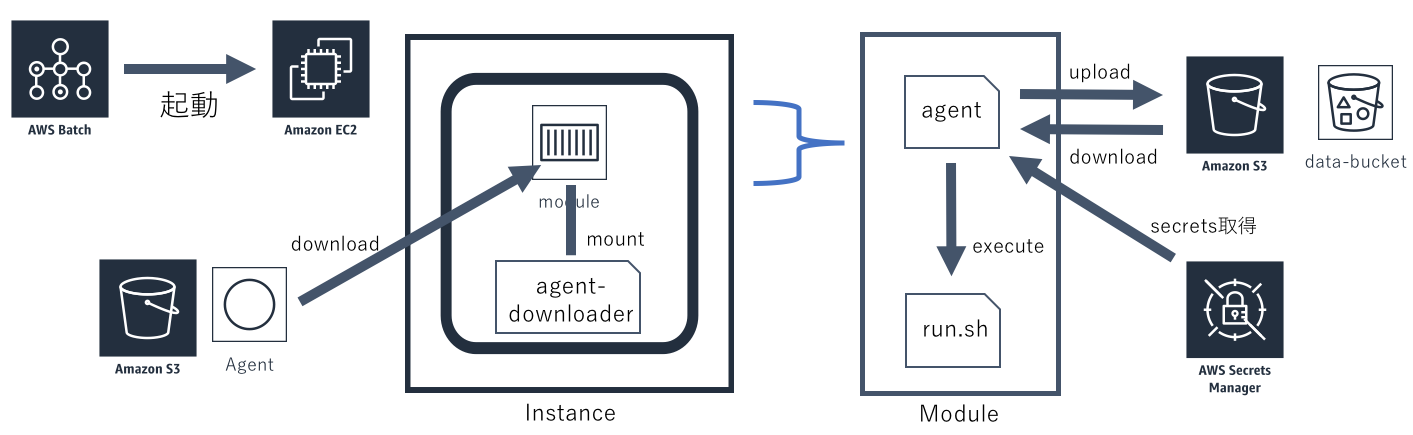
AWS Batchから起動されたEC2のAMIには、あらかじめエージェントのダウンロードスクリプトが保存されています。 そのスクリプトをマウントした状態でコンテナが実行されます。
コンテナのcommandは上書きされており、マウントされたダウンロードスクリプトが実行されるようになっています。 ダウンロードスクリプトは最新版のエージェントをダウンロードし、実行します。
エージェントはワークフローの定義にしたがって、S3からデータのダウンロードやSecretsManagerから秘匿情報の取得を行います。 その後、モジュールのメインとなる処理を行い、出力されたファイルをS3へアップロードします。
ワークフローの実行ステータスのイベントを取る仕組み
Step FunctionsとAWS Batchを組み合わせることで、マネージドサービスにワークフロー実行の制御をすべて任せられます。 これは高いスケーラビリティを実現できる要因となっており、負荷試験において500個同時にワークフローを実行しましたが、まったく問題ありませんでした。
反面、ワークフローの実行ステータスをアプリケーション側で持てないという問題があります。 アプリケーションはStep FunctionsのStateMachineを実行するだけで、その後はすべて任せているので、ジョブが正常に終わったのかどうかを知るすべがありません。 CloudWatchEventsからStateMachineのExecutionのステータス遷移が取れないか試しましたが、それもできないようです。
これはワークフロー実行終了時に何かを行うのが難しいということを表します。例えば失敗時にSlackへ通知するといったことです。
成功時に通知するのであればStateMachineの最後にそれを行うLambdaを入れるだけで実現できます。 しかし失敗時となるとASLの各所にCatchを入れるなどの工夫が必要になってきます。 各所にCatchを入れるのは冗長ですし、Catch後に複数の処理をするのも大変です。
そこでStateMachineのExecutionのステータスをDynamoDBに同期する仕組みを作りました。 DynamoDBに同期さえされていれば、DynamoDB Streamsを使ってステータス遷移イベントを取得できます。 そのイベントをSubscribeするLambdaを複数紐付けることも簡単にできます。
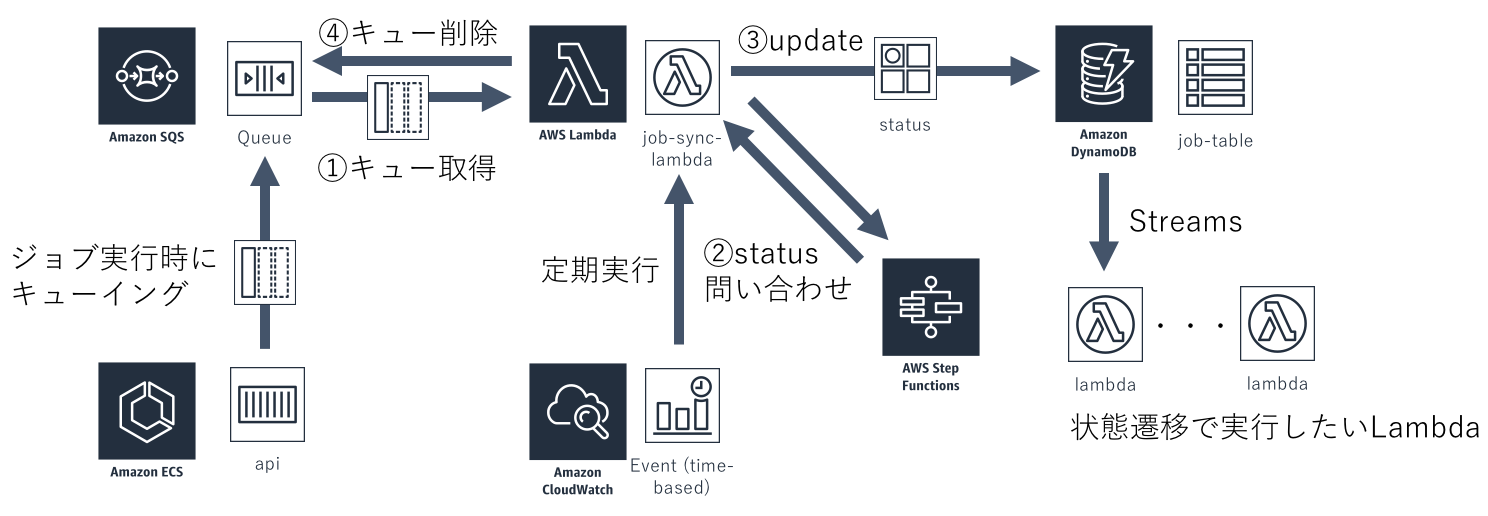
まずワークフローの実行を受け付けたAPIはSQSへキューを積みます。 ステータス同期を行うLambdaはCloudWatchEventsから定期実行されており、キューをポーリングしています。
次にキューの取得ができたLambdaはStep FunctionsのAPIへExecutionのステータスを問い合わせます。 ステータスに変更があった場合にDynamoDBに書き込みます。
ステータスが完了・失敗になっていた場合キューを消して処理を終えます。 そうでなかった場合は、キューはそのままにしておき、次の定期実行で再度ステータスを確認して同期するという流れです。
この仕組みを使ってワークフローの失敗時にSlackへ通知する機能が実現されており、今後は設定したURLへジョブのステータスをコールバックする機能にも利用する予定です。
秘匿情報と生成されるデータを保護する仕組み
ワークフローの実行においてはAWSのアクセスキーといった秘匿情報をモジュールに渡す必要があることがあります。 その秘匿情報は他ユーザーからはアクセスできない状態にする必要があります。 またモジュールが生成するデータも他のユーザーからアクセスできないように保護されているに越したことはありません。
こうしたセキュリティ要件を満たすためにIAM RoleとKMSキーを使った暗号化と復号を制限する機構を作りました。
具体的には、まずワークフローの所有グループ(プロジェクトと呼んでいます)ごとにIAM Roleが1つ発行されます。 そのIAM Roleからのみ復号できるようにPolicyを設定したKMSキーを作成しておきます。
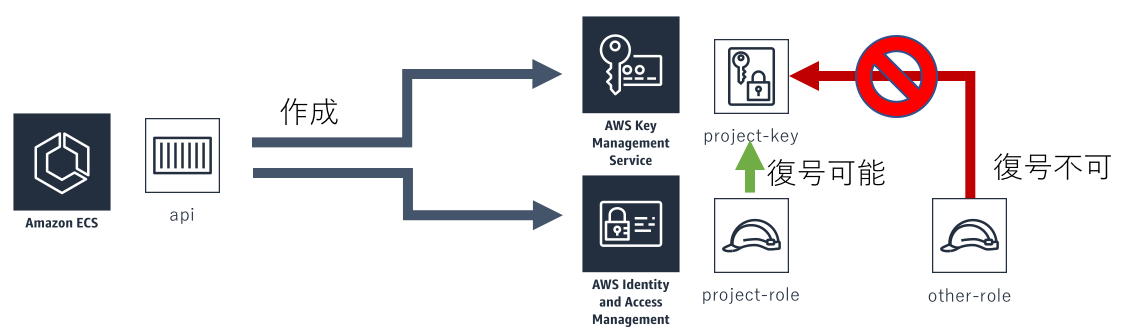
秘匿情報はSecrets Managerに保存しています。 Secrets Managerには、保存する際にKMSキーを指定できる機能があります。 そこで先ほど作成したKMSキーを指定することで、該当のプロジェクトからしか取得できない状態になります。
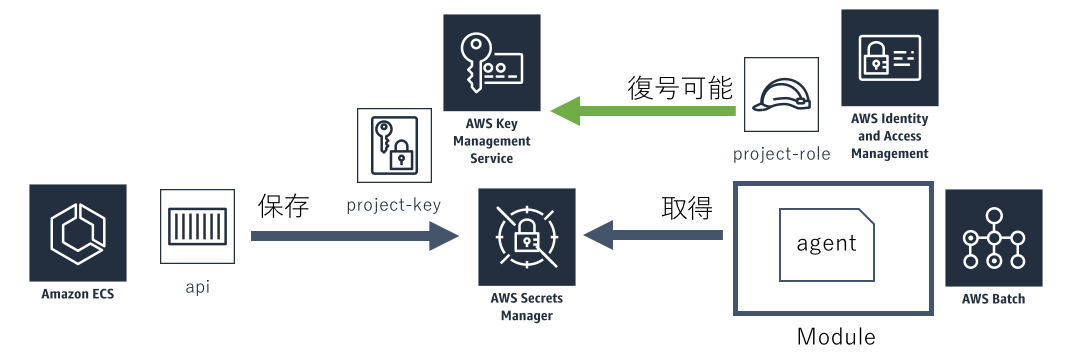
モジュールが生成するデータの場合も同様の仕組みでセキュリティを実現しています。 S3にもファイルをPutするときに暗号化キーを指定できる機能があります。 この暗号化キーに先ほどのKMSキーを指定することで、特定のIAM Roleからしか取得できない状態にできます。
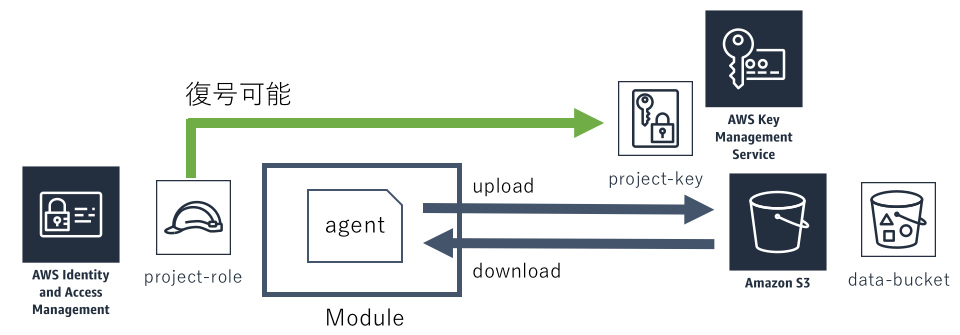
AWS Batchの実行コンテナには、プロジェクトのIAM Roleが割り当てられておりKMSキーで復号できるため、どちらの場合も問題なく取得できます。
このような実装をとることでCroisの開発者であっても暗号化されたデータを復号できない強固なセキュリティを実現することができました。
まとめ
AWSのマネージドサービスをうまく使うことでスケーラビリティとセキュリティを両立したジョブスケジューラを作成することができました。 運用負荷も低いためエンジニアは新しい機能開発に集中できています。
こうしたインフラを一から作るのは大変なことだと思うので、必要な機能が揃った実行環境が簡単に手に入るようになったのは大きいと感じています。 ITプランナー・データサイエンティスト・エンジニアの三者に有益なシステムを作ることができました。
広告
RCOアドテク部では一緒に使いやすいデータ分析基盤を作ってくれる優秀なエンジニアを募集しています。
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)