AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
はじめまして、アプリエンジニアの山本です。 インフラエンジニアの徳原と共にGoogle Cloud Next 2017に参加してきました。
 KeyNote開始直前の様子
KeyNote開始直前の様子
RCOは、リクルートグループ各社に横断で関わる機能会社です。その提供している機能の一つとして、リクルートグループの各Webサイトにおけるユーザーの行動ログを収集する、というものがあります。 収集されたログは最初ファイルに保存されるのですが、ファイルのままでは分析を行うには不便なため、分析に適した形に変換した上で分析用のデータベースに保存する必要があります。 私はこのデータ変換&保存処理の実装に携わっており、その立場からGoogle Cloud Platform(以下GCP)における最新の大規模データ処理事情を知る!という観点でセッションを選びました。
幾つかセッションを聴講する中で最も強く感じたのは、GCPではどれだけ大規模なデータでも処理できる、というだけでなく、データが得られてから分析用の環境に保存されるまでの待ち時間を短く出来る、というアピールです。
GCPでのデータ処理はまずデータをPub/Subにキューイングして、Dataflowで変換し、BigQueryに格納する、というアーキテクチャになるようで、下記のThe New York Timesでの事例に似た図が複数のセッションで提示されていました。
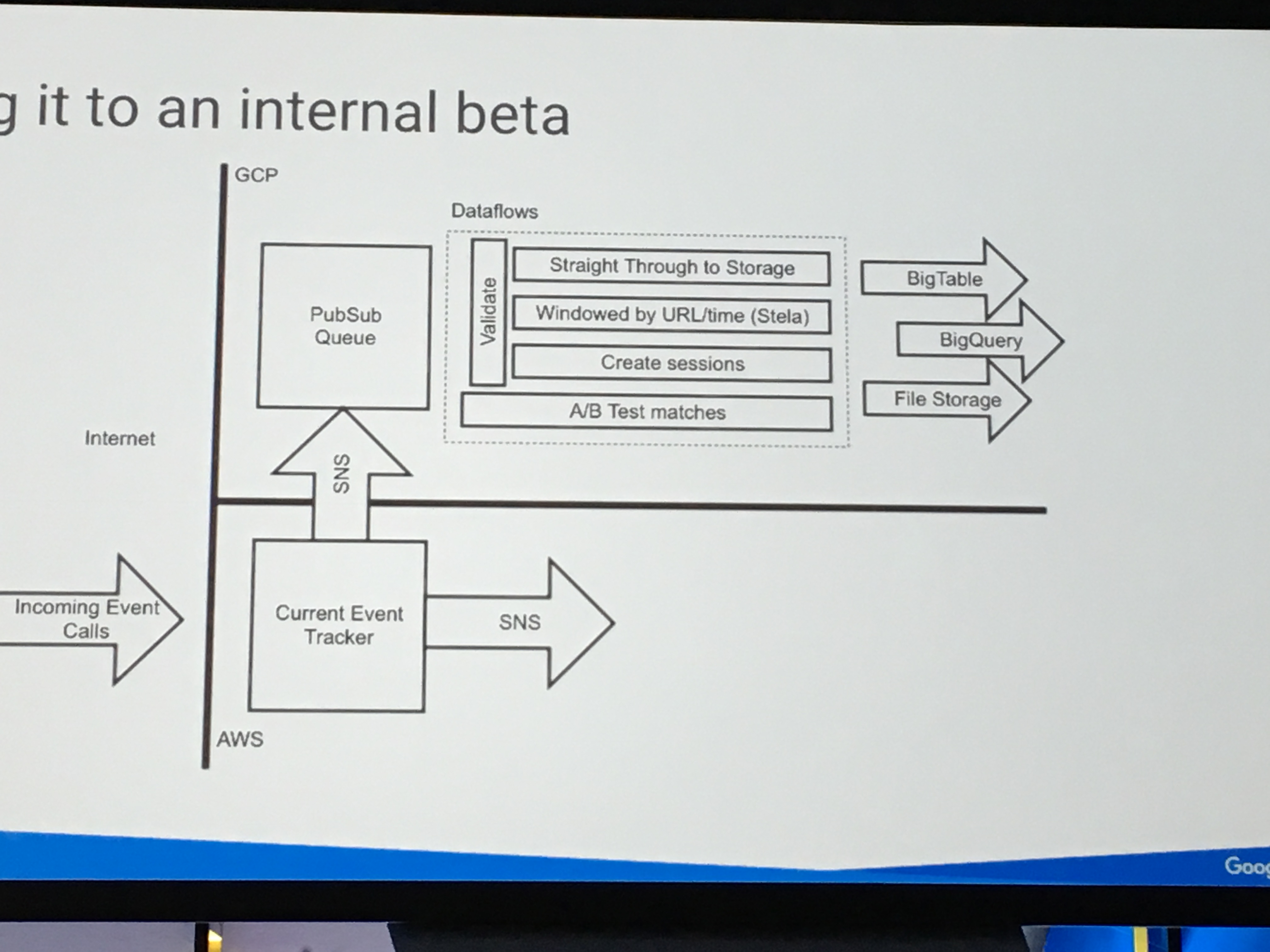 The New York Timesの事例
The New York Timesの事例
ただこのアーキテクチャで、Pub/Subのデータ保持期間が最大7日間なのを、もっと長く出来るといいな〜と考えています。 というのも、後段のDataflowにおける変換処理を変更した際に、7日間より前のデータにも変更を適用したい場合があるからです。 Pub/Subに相当するオープンソースソフトウェアはKafkaになると思います。自前でKafkaを運用すればデータ保持期間の制限は自由に決められるわけですが、私はできるだけマネージドサービスを使って楽をしたい派なので、GCPでなんとか出来るようになることを期待します・・・。
またGCPにおけるデータ並列処理モデルであるDataflowを、Apache Beamの下でプログラミングモデル標準化したとのことです。標準化されていると、仮にGCPを使用しなくなった、という場合でも知識を流用できてありがたいですね!
 データ処理のプログラミングモデルを規定するApache Beam
データ処理のプログラミングモデルを規定するApache Beam
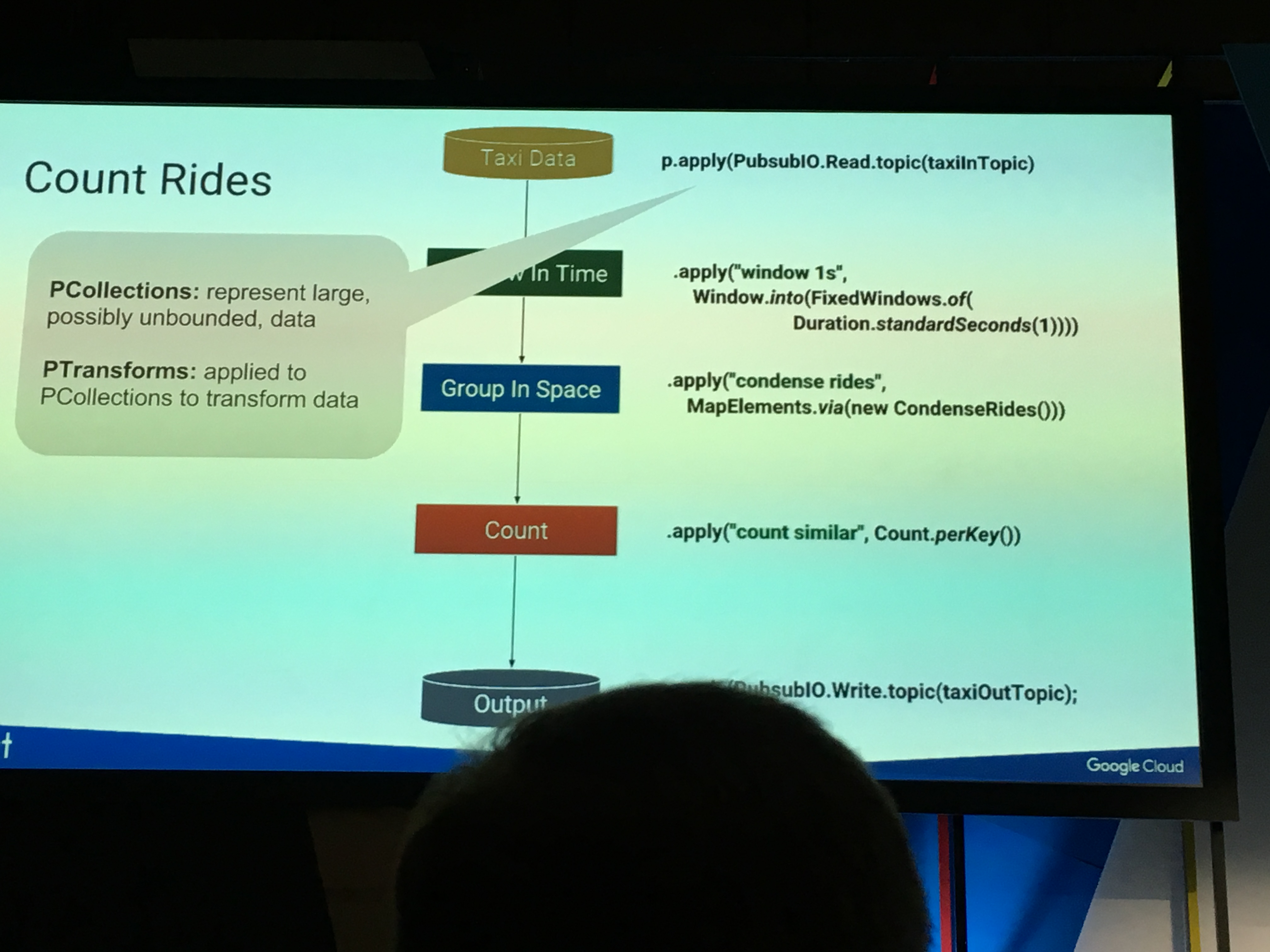 DataflowによるApache Beamの実装
DataflowによるApache Beamの実装
その他、Dataprepという新しいデータ変換サービスが提供されるようです。GUIでデータ変換を定義できるらしいのですが、エンジニア的にはコードでも構成管理できると嬉しいですね。
まだプライベートベータのため詳細不明です。早速ベータにサインアップしましたので、利用可能になりましたら改めてこのブログでレポートしたいと思います。
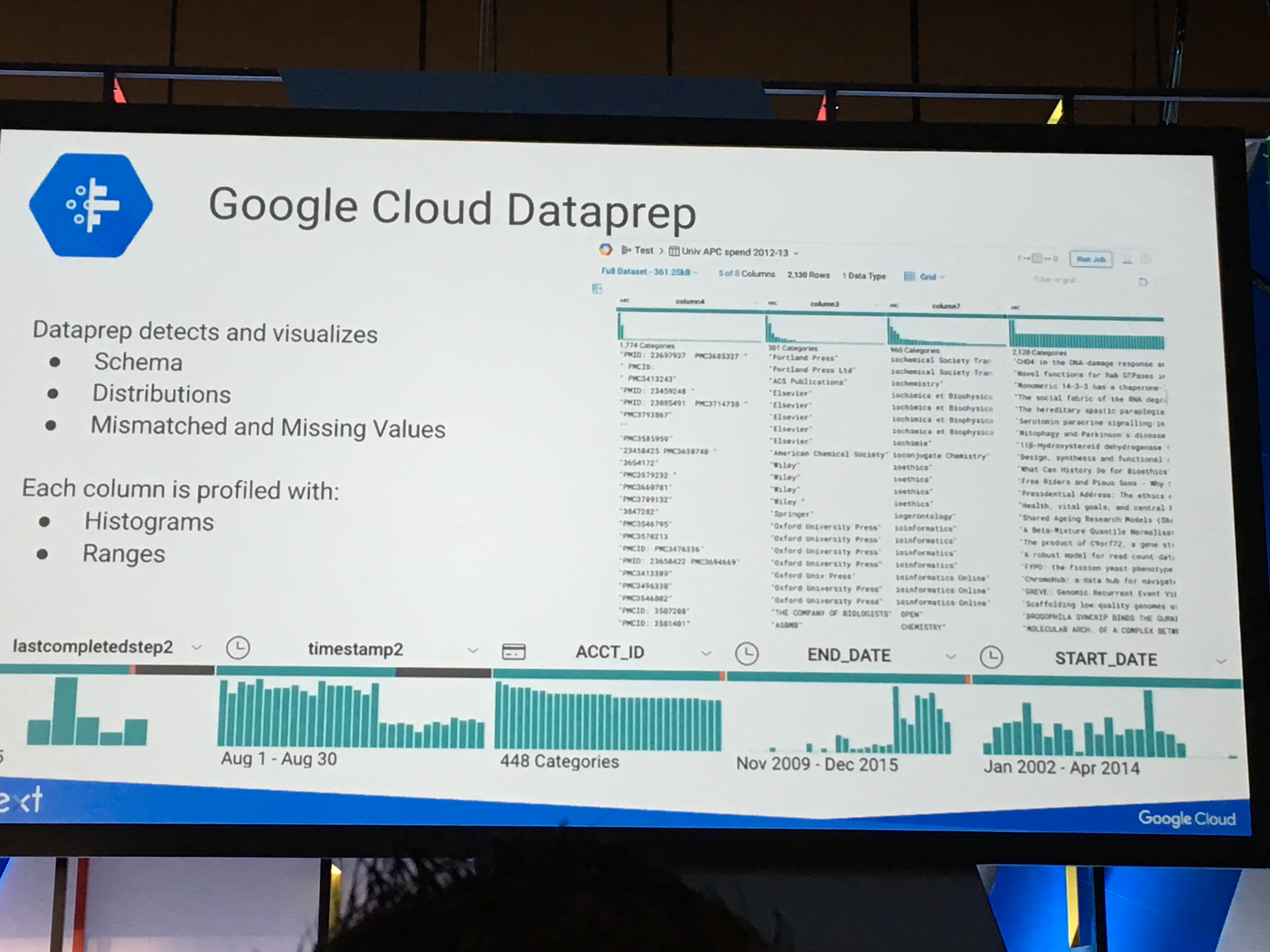 Dataprepによるテーブルのスキーマやデータの分散表示
Dataprepによるテーブルのスキーマやデータの分散表示
おまけ
KeyNoteからは、誰でも機械学習が利用できる環境を作っていく、(Kaggleの買収で表されるように)Googleは機械学習で先んじている、そのためのインフラも用意している、なので皆さんGCPを使ってください、というメッセージを感じました。 私のような機械学習は門外漢のアプリエンジニアでも、APIさえ呼び出せばなんとなく機械学習が出来てしまう時代がもう来ているようです。
その他、1日目のFei-Fei LiというChief Scientistの方のプレゼンがとても上手で感銘を受けました。エンジニアもコードだけ書いていればいい時代ではないですね・・・。
広告
RCOアドテク部では大規模データをリアルタイムに処理できる環境を構築してみたい、というエンジニアを募集しています。
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)