AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
サンフランシスコ3日目、旅の疲れからか不幸にも黒塗りの自動運転車に追突してしまうところでした、機械学習エンジニアの高柳です。
現在、私はサンフランシスコで開催中の Association for the Advancement of Artificial Intelligence (AAAI) に参加しており、 この記事はその3日目の参加記録になります。
この参加報告では、現地から毎日、リアルタイムに、私が参加したセッションの様子を報告していきます!
AAAI-17/IAAI-17 Joint Invited Talk
元Google自動運転部門がスピンアウトした会社であるWaymoのDmitri Dolgov氏による講演です。 氏はかつて米国のトヨタでも自動運転の研究開発を行っていたようです。
講演では自動運転の歴史からはじまり、自動運転をしていく上で如何に物体を認識・分類することが大切かや、これからの自動運転が抱える問題について講演されていました。 講演の中で「自分達は自動車メーカーではなく、あくまで自動運転を行うソフトウェアを作る会社である」と何回か主張されていたのが印象的でした。 やはりベイエリア(Not シリコンバレー)らしくソフトウェア(+自動運転に必要なハードウェア)で攻めるということでしょうか。
個人的に面白かったのは「蛙跳びをしながら横断歩道を渡っている歩行者は歩行者と認識されなかった」という話の下りです。 完璧な認識への道は険しい…
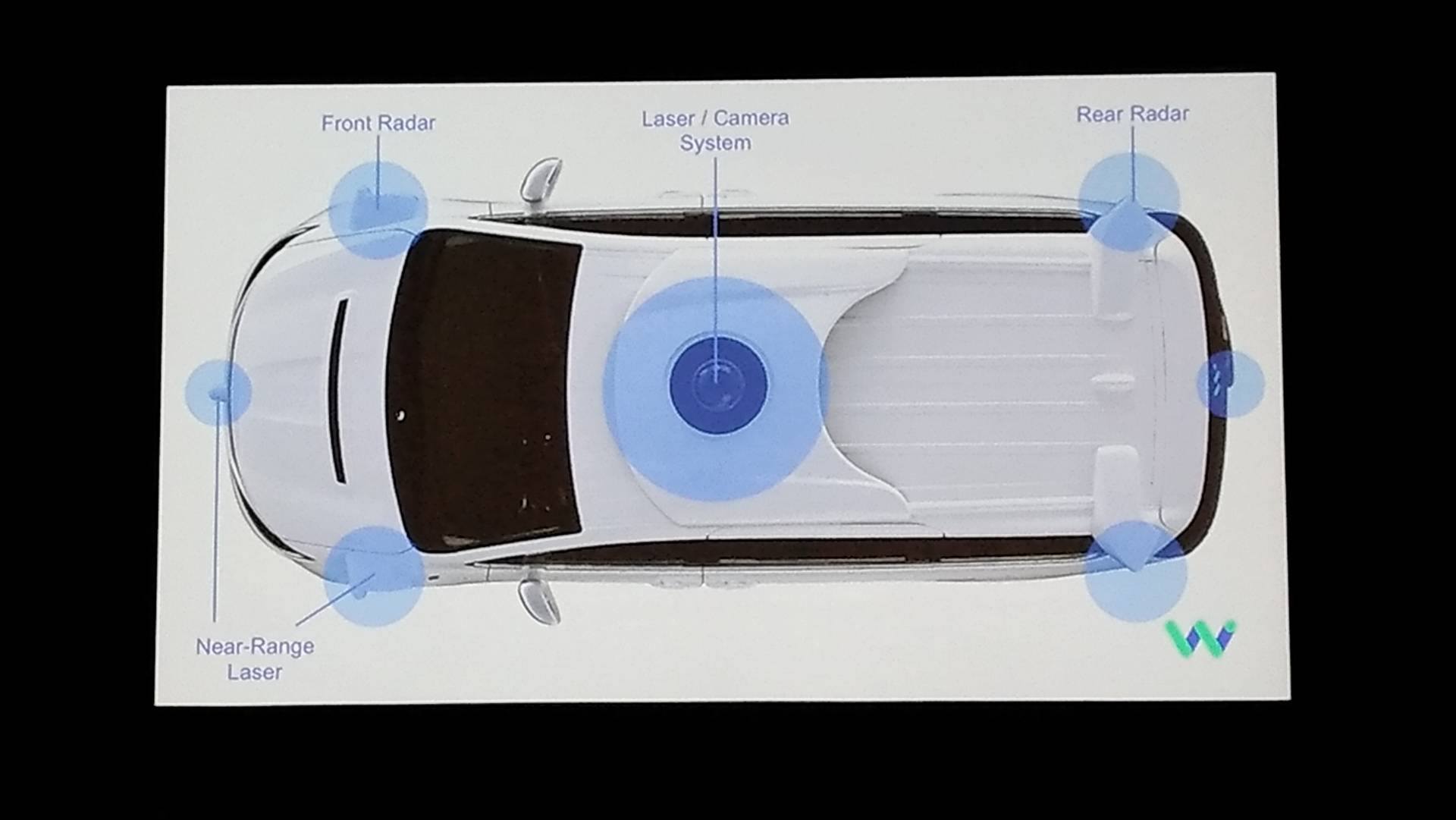
図:自動運転車につけているレーダーなどのハードウェアの概説
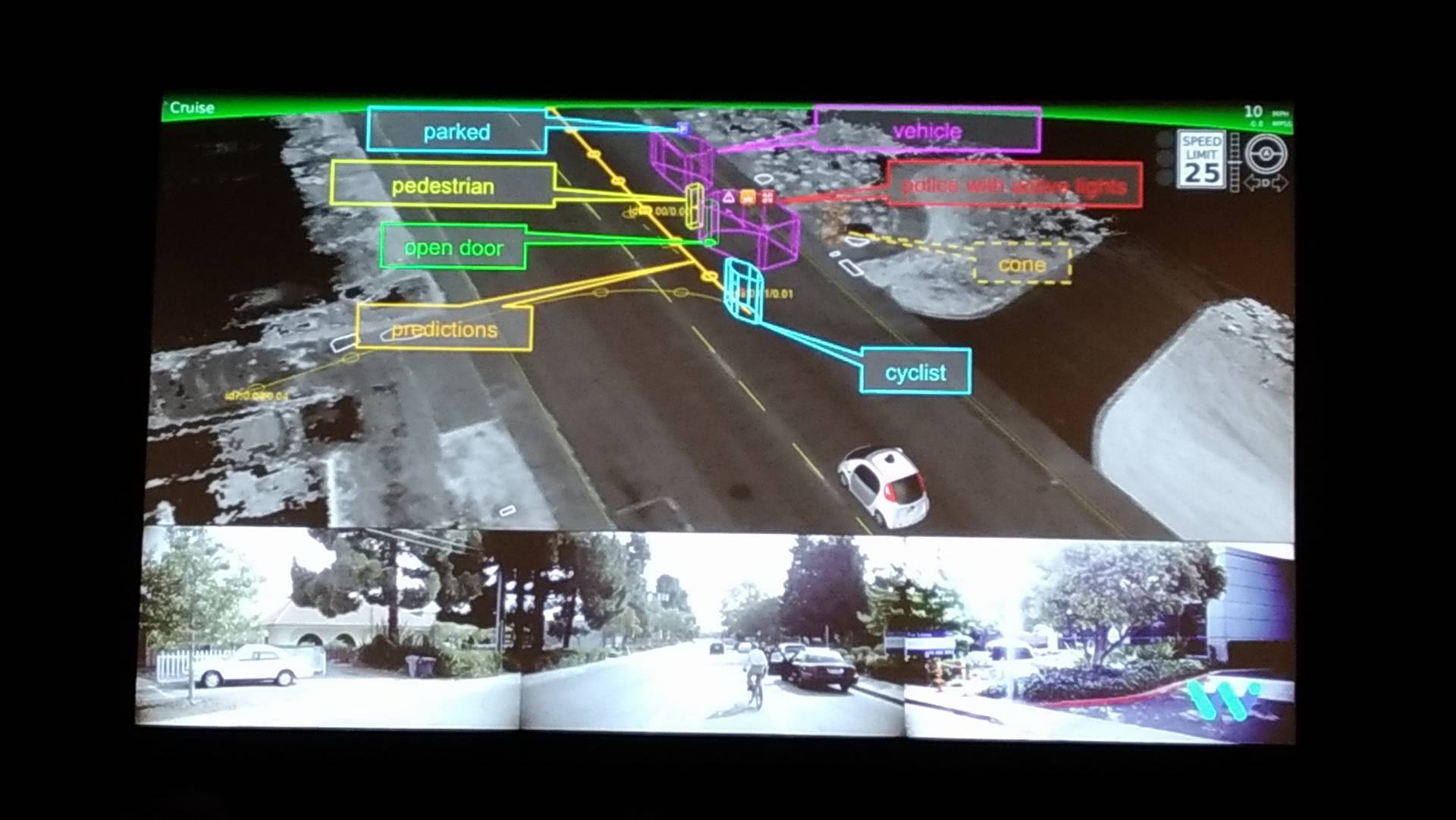
図:実際の自動運転車が歩行者・車・自転車などをどう認識しているか
HSO4: Optimization (plus one Senior Member presentation)
よく扱われる凸な最適化問題ではなく、非凸の最適化問題に対し、 非同期な分散減少法を活用したStochastic Gradient Descent(SGD)法であるASVRG(Asynchronous Variance Reduced for Gradient Descent)の提案や、 同じくSGDの拡張である低ランクなDML(Distance Metric Learning)、 そして、認知アーキテクチャの包括的なレビューと現状抱える課題(推論・感情・メタ認知など)についての講演がありました。
ML21: Data Mining and Knowledge Discovery
「Streaming Classification with Emerging New Class by Class Matrix Sketching」 というタイトルの講演が気になり、これのみを聴講するために、このセッションに参加しました。 元になっている論文はコチラの模様。 「既存のクラスの分類も行え、かつ、新たなクラスとして分類すべきデータを見つけることができ、更にストリーミングデータを活用しモデルの更新もできる」 ような手法を提案しています(SENC-MaSと呼称)。
この方法は、入力データを荒く近似したグローバルスケッチングと呼ばれる行列と、 ある特定のクラスのデータのみを荒く近似したローカルスケッチングと呼ばれる行列を導入(ある種の次元圧縮)。
その後、データからこれらの行列を学習させ、グローバルスケッチング行列(の各行)と評価したいデータの内積を計算し、 その最大値がある閾値(論文では全学習データのグローバルスケッチング行列(の各行)との内積の最大値の平均)を 下回っていれば新規クラスに属すべきデータと判断します。 また、既存のクラスに対する分類は上と同様の操作をローカルスケッチング行列に対して適用します。
シンプルでキレイな枠組みなので、これももう少し深掘りしたいところです。
IAAI-17: Sense-Making: Using Automated Systems to Pull Out Patterns and Structure from Data
「Automated Data Cleansing through Meta-Learning」 という、データサイエンティストにとっては夢の技術に聞こえる講演を聴講しにこちらへ。 元になってる論文はコチラの模様。
メタラーニングを活用し、所謂(広義の)前処理(欠損補完、標準化、特徴量削減、不均衡調整など)を自動化してしまおうという野心的な企みです。 皆さん、やはりここが急所というか、興味あるところのようで多数の方が聴講しに来ていました。 この研究では「データをベクトル表現に倒し(これをメタ特徴量と呼称)、これがある多様体上にあると仮定し、 この多様体上で(なんらかの意味で)近いデータセットには同じ前処理を適用する」というのがベーシックな考え方です。 言葉で説明するのが難しいのですが、これは元になってる論文の図1をみると良いです。
論文では「多様体上で”近い”はどう表現されるべきか?」という課題に対し、複数の”距離”(Lpノルムなど)に対して正しいデータ処理前処理が選択されるかを評価しています。 結論としては、メタ特徴量(データの多様体上へのマッピング)がうまく構成されておらず、ここをより良いものに変えることが必要であると結んでいます。 結んではいますが、非常に挑戦的で面白い話でした。
ML22: Dimensionality Reduction / Feature Selection
最小二乗法に対し、”計算量を圧縮させる”・”推定をロバストにさせる”という2つの特徴を付した”Robust Partially-Compressed Least-Squares”という手法の提案がありました。 元になっている論文は(多分)コチラ。 計算量の圧縮はSVDを通して次元削減された行列を最小二乗計算時の”重み”として適用することで達成、 またロバストな推定の達成にはよくあるLasso・Ridgeな回帰として罰則項を不可した最適化計算を行うのではなく こちらの書籍に 詳細のあるエラー構造を陽に指定できるロバスト推定を用いているとのこと。 更に、回転に対して不変となるロバストな計算次元削減手法(主成分分析ベース、主に2次元画像を想定)の提案や、 不均衡データに対する特徴量選択としてAccuracyではなく拡張したF値(Fβと呼称)を導入、これを用いて目的関数を構築&最適化し、 マジョリティなクラスにバイアスがかった特徴量選択をしない手法、 また、電子化されたヘルスデータ(EHR, Electronic Health Records)から 入退院や医療支出を予測(分類)するためのテンソル分解を活用した手法”Task Guided Tensor Decomposition(TaGiTeD)“の提案についての講演がありました。
個人的には”Robust Partially-Compressed Least-Squares”が一番気になるところです。
AAAI-17 Invited Talk
テキサス大学のKristen Grauman准教授によるInvited Talk(本日2件目)です。
現在、深層学習で行われている大量の区別しやすいラベル付の画像から学習させるのではなく、 実際に動いたり行動している状況にある動画から学習を行うためにはどうするかという内容の講演でした。 Invitedのトークの中でも研究自体の成り立ちから実際に今行っていることまでを、モデルの数式解説まで含めて丁寧に行っており、非常に勉強になりました。
特に特徴量の”同値(equivariance)“を仮定してモデリングしている点は、Web系のデータを活用した機械学習ではなかなかお目にかからない、 画像や動画の持つ数学的な美しい構造を久しぶりに感じることができ、面白かったです。
本質的には、「動く自分(カメラ)の動きから、目(カメラ)に写る周囲の環境がどう変わるのかを学習させる」とのこと。 機械学習の言葉に置き換えるなら、教師なし学習を「ラベルのない動画、及びカメラの位置・速度などのデータ」から学習させるようです。


図:不変(Invariant)と同値(Equivarant)の違いの説明

図:動画データのフレーム間の関係に対し、不変と同値で、何を要請するのかの違いの説明

図:360度カメラの画像とその動きから、特定の位置を抽出
使用しているコードなどはコチラから入手可能とのこと。
速報につき、内容の詳細が間違っていたら是非ご指摘ください。
・・・参加3日目の現場からは以上です。
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)