AD-TECH
NEWS
- リクルートデータ組織のブログをはじめました。※最新情報はRecruit Data Blogをご覧ください。
- Recruit Data Blogはこちら
エンジニアの棚橋、そして、マッドサイエンティストの佐野です。 今年も残りわずかとなりましたが、みなさんごきげんいかがでしょうか。 2016年、リクルートコミュニケーションズ, アドテク部は量子コンピューティングに参入(ZDNet: Googleやリクルートが取り組む理由–量子アニーリング理論の可能性)するなど、マッドに始まりマッドに終わる1年となりました。
そんな1年を締めくくるべく、今回我々は機械学習のトップカンファレンスの一つであるNIPSに参加してきました。 昨年は氷点下の中、カナダのモントリオールで開催されたNIPSですが、今年は日本よりも比較的温暖なバルセロナで開催されました。 参加者数は過去最高の5680人、会場は人で溢れかえり、改めてAIブームの凄さを実感したわけであります。 会場で話した人の中には機械学習の研究・開発を行っているわけではなく、技術調査やリクルーティング目的で来ている方もいて、NIPS参加者の層の広さを感じました。

昼休みは意外と時間があり、グエル公園やサクラダファミリアに観光に行きました。グエル公園に行ってもなおディープラーニングの話をしている人がちらほらといて、街全体がNIPS参加者に占領されているという感じでした。 (image ref:http://www.howtravel.com/)
今まで配られていたカンファレンス冊子は今年からはオプションとなり、希望しない人へは配布しない形となりました。
代わりにWhovaという学会イベントアプリが導入されました。
このアプリでは、参加者のプロフィール検索や、掲示板やチャット、
発表のスケジュール、アブストなどを見ることができ参加者同士の交流に役立ちました。
今年の発表はディープラーニングの話題が最も多く、learning theory、computer visionなどのトピックがそれにつづきましたが、特にリアリスティックな画像を生成するネットワークのGAN(Generative Adversarial Network)が非常に盛り上がりました。LeCunも”the coolest idea in machine learning in last 20 years”[ref]と形容するほどで、 チュートリアルセッションではGANの生みの親であるGoodfellowが、min-maxゲームの基礎から最新の話題まで生き生きと話していました。 セッションの中では、画像にペイントで色を塗るとスムーズにその色に合わせて画像全体も変化していくデモ映像も紹介され、GANがいかにおもしろいかを体感することができました。
- https://www.youtube.com/watch?v=FDELBFSeqQs
- Neural Photo Editing with Introspective Adversarial Networks [ref]
GANの分野はとくに研究スピードが速く、3Dモデル、動画、言語処理など、さらに応用領域を広げているようでした。
NIPSでは約500の研究が発表され、ここですべてを紹介しきることはできませんが、以下では個人的に面白いと思ったものをいくつか紹介したいと思います。
ちなみに2017年2月頃にNIPS&ICDM読み会を企画中です。詳細決まり次第にお知らせします!
Fast and Provably Good Seedings for k-Means[ref]
k-means++は質の良いシードを生成するが、計算量が大きいという問題がありました。提案手法ではk-means++をMCMCで近似することで、k-means++と比べて数千倍も計算量を減らすことができたという内容です。我々は業務でk-meansを扱う機会が少なくないため、とても実用的でおもしろい研究でした。
Data Programming: Creating Large Training Sets, Quickly [ref]
教師あり学習の課題の一つは教師データを大量に作成することが大変だということです。提案手法では、静的な教師データにより学習するのではなく、データXから教師データを作成するラベル関数Y(X)をエキスパートによって複数作成し、この関数のノイズを考慮した上で最終的に汎化誤差を最小にするような識別器を構築するというアイデアです。”Data Programming”はルールベースの手法と機械学習の手法の良いところを組み合わせて既存の問題を解決するおもしろい概念です。簡単な例だと、テキストのラベル付けタスクなどですぐにでも業務で使えそうだなと思いました。
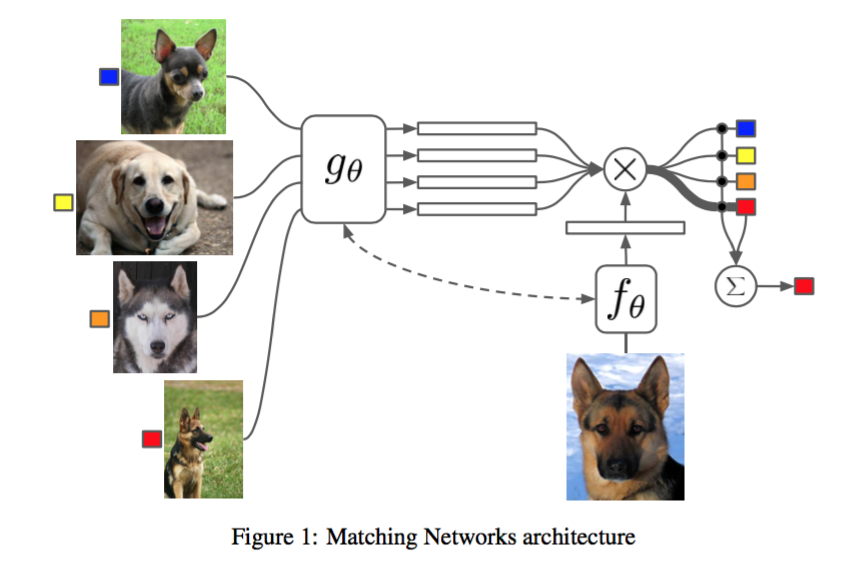
Matching Networks for One Shot Learning [ref]
いま話題のlearning to learn:メタラーニングに関する研究。5つほどの候補画像の中からクエリ画像と同じクラスに属するものを選ぶというタスクを、未だ見ぬクラスに対して行うというものです。候補画像Sによって画像のembedding g(x)を変化させる必要があり、この部分をattentionを使ったLSTMで実装。候補画像によってembeddingを変えることで近い画像が候補に含まれていても適切に同じクラスが選択できるようにしたというアイデアがすごい。
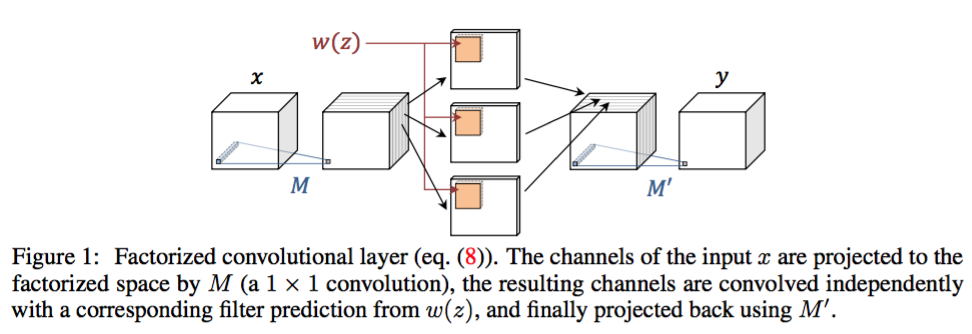
Learning feed-forward one-shot learners [ref]
上と同じ、learning to learn。映像の最初の1コマの画像に写っている物体を一度だけモデルに与え、以降の映像のフレーム中から切り出した画像がその物体を含むかどうかを当てる二値分類を考えています。学習データを一つしか与えられないとモデルはoverfitしてしまうので、ドメイン知識をいかにpriorとして学習に組み込むかが肝となります。ここでは、クエリ画像から動的にパラメータを生成し、そのパラメータを使って、同一かどうかの二値分類を行うことでこれを解決しています。 また、overfitを防ぐために、パラメータの数を劇的に減らす”Factorized convolutional layers”と呼ばれる手法を導入しています。end-to-endにメタな学習が達成されているというのはやはりすごく、2017年にはこのメタラーニングがさらに流行るのではないかと思います。
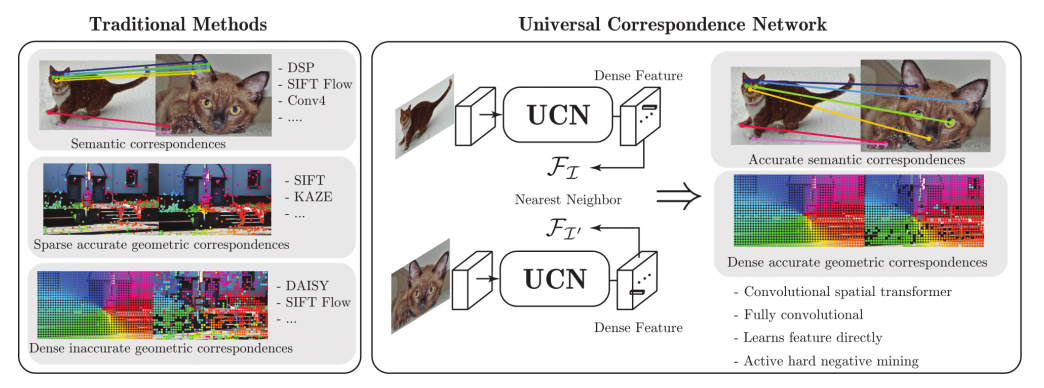
Universal Correspondence Network [ref,デモ動画]
Convolutional Neural Networkを使った画像のDescriptor。Descriptorの典型的な利用法として、画像のある点に対して、別の画像の対応する点を検出するというタスクがあり、従来はSIFTやORBといったdescriptorが使われてきました。従来手法では、対応する2点の候補が本当に一致しているかどうかを一つ一つ調べていくという過程を経る必要があるため、計算量がO(n^2)となります。提案手法では画像中のすべての点を特徴空間に埋め込み、特徴空間での距離が閾値以下の2点が対応点となるため、理想的にはO(n)の計算量になります。もう一つ面白いところは、従来手法のSIFTやORBでは画像の見た目の特徴から対応点を検出しますが、この手法ではセマンティックな対応点を検出することが可能です。例えば、下の画像中では鳥のクチバシに対して全く違う鳥の対応するクチバシの部分を検索することができています。

後編ではここでは紹介しきれなかった研究をさらに紹介していく予定です!
ARCHIVE
- 月別記事リストを見る
-
- 2020年03月 (2)
- 2019年09月 (3)
- 2019年08月 (1)
- 2019年06月 (1)
- 2019年03月 (5)
- 2019年02月 (3)
- 2018年09月 (1)
- 2018年06月 (2)
- 2018年05月 (2)
- 2018年04月 (1)
- 2018年02月 (1)
- 2018年01月 (1)
- 2017年12月 (2)
- 2017年11月 (1)
- 2017年10月 (1)
- 2017年08月 (1)
- 2017年07月 (2)
- 2017年06月 (1)
- 2017年05月 (3)
- 2017年04月 (5)
- 2017年03月 (12)
- 2017年02月 (16)
- 2017年01月 (1)
- 2016年12月 (1)
- 2016年08月 (1)
- 2016年06月 (5)
- 2016年05月 (2)
- 2016年04月 (1)
- 2016年03月 (3)
- 2016年02月 (8)
- 2016年01月 (3)
- 2015年12月 (2)
- 2015年03月 (1)
- 2015年02月 (2)
- 2015年01月 (3)
- 2014年12月 (2)
- 2014年11月 (3)
- 2014年10月 (1)
- 2014年09月 (2)
- 2014年07月 (1)
- 2014年04月 (2)
- 2014年03月 (3)
- 2013年12月 (1)
- 2013年11月 (1)
- 2013年10月 (5)